 SRE as a Service
SRE as a Service DevOps as a Service
DevOps as a Service Cloud & Kubernetes migration
Cloud & Kubernetes migration Infrastructure & CI/CD audit
Infrastructure & CI/CD audit R&D and technology consulting
R&D and technology consulting Kubernetes support
Kubernetes support Solution for SaaS
Solution for SaaS All services
All services
This article describes a real-life case we recently encountered: the Kubernetes API was paralysed by a large number of requests in one of the clusters. Today, we are going to talk about how we dealt with this problem and provide some tips on how to prevent it.
How multiple requests broke the Kubernetes API
One very ordinary morning, our journey embarking on a lengthy study of the Kubernetes API and prioritisation of requests to it began. We received a call from a tech support engineer who reported that a customer’s cluster was practically non-operational (including the production environment) and said that something had to be done about it.
We connected to the failed cluster and saw that Kube API servers had eaten up all the memory. They would crash, restart, crash again, and restart again over and over. This ended up rendering the Kubernetes API inaccessible and completely non-functional.
Since this was a production cluster, we put a temporary fix in place by adding processors and memory to the control plane nodes. The resources we added at the beginning were insufficient. Fortunately, after the next batch of resources, the API stabilised.
Seeking out the root of the problem
First, we assessed the extent of the changes we ended up having to make. Initially, the control plane nodes had 8 CPUs and 16 GB of RAM. Following our intervention, their size increased to 16 CPUs and 64 GB of RAM.
Below are the memory consumption graphs at the moment that the problem occurred:
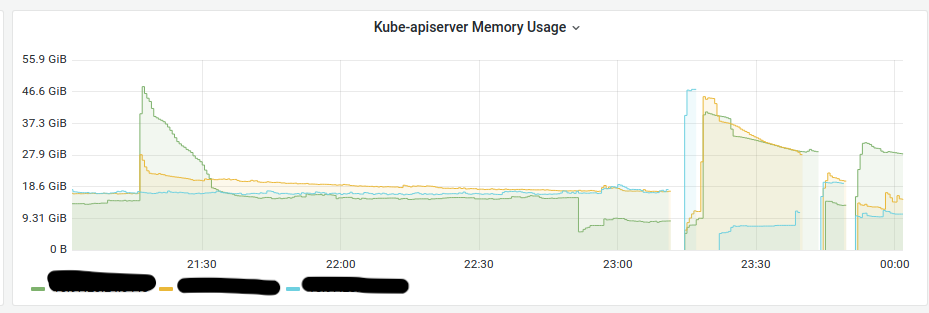
Memory consumption was as high as 50 GB. Later, we discovered that, due to certain factors, the Cilium pods were sending LIST requests to the API en masse. Since the cluster was large and had a large number of nodes (more than 200), simultaneous requests greatly increased the amount of memory being used.
We agreed with the customer to operate a test window, restarted Cilium agents, and we came to discern the following scenario:
- The load on one of the API servers was growing.
- It consumed memory.
- It ate up all the memory on the node.
- And then crashed.
- The requests were redirected to another server.
- Then, the same thing happened again.
We thought it’d be a good idea to limit the number of simultaneous cilium-agent requests to the API. In that case, slightly slower LIST request execution would not affect Cilium’s performance.
The solution
We created the following FlowSchema and PriorityLevelConfiguration manifests:
---
apiVersion: flowcontrol.apiserver.k8s.io/v1beta1
kind: FlowSchema
metadata:
name: cilium-pods
spec:
distinguisherMethod:
type: ByUser
matchingPrecedence: 1000
priorityLevelConfiguration:
name: cilium-pods
rules:
- resourceRules:
- apiGroups:
- 'cilium.io'
clusterScope: true
namespaces:
- '*'
resources:
- '*'
verbs:
- 'list'
subjects:
- group:
name: system:serviceaccounts:d8-cni-cilium
kind: Group
---
apiVersion: flowcontrol.apiserver.k8s.io/v1beta1
kind: PriorityLevelConfiguration
metadata:
name: cilium-pods
spec:
type: Limited
limited:
assuredConcurrencyShares: 5
limitResponse:
queuing:
handSize: 4
queueLengthLimit: 50
queues: 16
type: Queue… and deployed them to a cluster.
It worked! Restarting cilium-agent resulted in no significant memory consumption change anymore. Therefore we were able to cut the node resources to their original ones.
What did we do and how those actions help eliminate the problem in case of multiple Kubernetes API requests? Read a breakdown below.
It is also a good moment to remind that recently we solved a similar problem for Vector pods as well. It even led us to creating a couple of pull requests to Rust-based Kubernetes-related projects…
Managing requests in the Kubernetes API
In Kubernetes, request queue management is handled by API Priority and Fairness (APF). It is enabled by default, in Kubernetes 1.20 and beyond. The API server also provides two parameters, --max-requests-inflight (default is 400) and --max-mutating-requests-inflight (default is 200), for limiting the number of requests. If APF is enabled, both of these parameters are summed up — and that’s how the API server’s total concurrency limit is defined.
That said, there are some finer details to account for:
- Long-running API requests (e.g., viewing logs or executing commands in a pod) are not subject to APF limits, and neither are WATCH requests.
- There is also a special predefined priority level called
exempt. Requests from this level are processed immediately.
APF ensures that Cilium agent requests do not “throttle” user API requests. APF also allows you to set limits so that it guarantees you important requests are always processed, regardless of the K8s API server load.
You can configure the APF using the following two resources:
PriorityLevelConfigurationthat defines one of the available priority levels.FlowSchemathat maps each incoming request to a singlePriorityLevelConfiguration.
Priority level configuration
Each PiorityLevelConfiguration has its own concurrency limit (share). The total concurrency limit is distributed among the existing PriorityLevelConfigurations in proportion to their shares.
Let’s calculate that limit by following the example below:
~# kubectl get prioritylevelconfigurations.flowcontrol.apiserver.k8s.io
NAME TYPE ASSUREDCONCURRENCYSHARES QUEUES HANDSIZE QUEUELENGTHLIMIT AGE
catch-all Limited 5 <none> <none> <none> 193d
d8-serviceaccounts Limited 5 32 8 50 53d
deckhouse-pod Limited 10 128 6 50 90d
exempt Exempt <none> <none> <none> <none> 193d
global-default Limited 20 128 6 50 193d
leader-election Limited 10 16 4 50 193d
node-high Limited 40 64 6 50 183d
system Limited 30 64 6 50 193d
workload-high Limited 40 128 6 50 193d
workload-low Limited 100 128 6 50 193d- First, sum up all the
AssuredConcurrencyShares(260). - Now, calculate the request limit, e.g., for the
workload-lowpriority level : (400+200)/260*100 = 230 requests per second.
Let’s change one of the values and see what happens. For example, let’s increase AssuredConcurrencyShares for deckhouse-pod from 10 to 100. The request limit will drop to (400+200)/350*100 = 171 requests per second.
By increasing the AssuredConcurrencyShares amount, we increase the query limit for a particular level but decrease it for all the other levels.
If the number of requests in the priority level is greater than the allowed limit, the requests become queued up. You have the option to customise the queue parameters. You can also configure the APF to immediately discard requests that go over the limit for the specific priority level.
Let’s take a look at the example below:
---
apiVersion: flowcontrol.apiserver.k8s.io/v1beta1
kind: PriorityLevelConfiguration
metadata:
name: cilium-pods
spec:
type: Limited
limited:
assuredConcurrencyShares: 5
limitResponse:
queuing:
handSize: 4
queueLengthLimit: 50
queues: 16
type: QueueHere, the priority level is configured to have AssuredConcurrencyShares = 5. If there are no other custom priority levels, this yields 12 requests per second. The request queue is set to 200 requests (handSize * queueLengthLimit), and 16 internal queues are created to distribute requests from different agents more evenly.
A few important details regarding priority level configuration in the K8s flow control:
- Having more queues reduces the number of collisions between flows, but increases memory usage. Setting it to
1disables fairness logic, but still allows requests to be queued. - Increasing the
queueLengthLimitrenders it possible to handle high-traffic bursts without overlooking a single request. However, the queries are processed slower and require a greater amount of memory. - By changing the
handSize, you can adjust the likelihood of collisions between flows and the overall concurrency available to a single flow in high-load situations.
These parameters are selected by way of experimentation:
- On the one hand, we need to make sure that requests at this priority level are not processed too slowly.
- On the other hand, we need to make sure that the API server will not be overloaded by a sudden traffic spike.
Flow schema
Now let’s move on to the FlowSchema resource. What it does is map requests to the appropriate PriorityLevel.
Its main parameters are:
matchingPrecedence: defines the order in whichFlowSchemais applied. The lower the number, the higher the priority. This way you can write overlappingFlowSchemasstarting from more specific cases to more general ones.rules: define request filtering rules; the format is the same as in Kubernetes RBAC.distinguisherMethod: specifies a parameter (user or namespace) for separating requests into flows when forwarding them to the priority level. If the parameter is omitted, all requests will be assigned to the same flow.
Example:
---
apiVersion: flowcontrol.apiserver.k8s.io/v1beta1
kind: FlowSchema
metadata:
name: cilium-pods
spec:
distinguisherMethod:
type: ByUser
matchingPrecedence: 1000
priorityLevelConfiguration:
name: cilium-pods
rules:
- resourceRules:
- apiGroups:
- 'cilium.io'
clusterScope: true
namespaces:
- '*'
resources:
- '*'
verbs:
- 'list'
subjects:
- group:
name: system:serviceaccounts:d8-cni-cilium
kind: GroupIn the example above, we pick all LIST requests to apiGroup: cilium.io, including cluster-scope requests and those sent from all namespaces to all resources. The subject includes all requests from the d8-cni-cilium service account.
How do I find out which FlowSchema and PriorityLevelConfiguration the request is in?
When responding, the API server supplies the special headers X-Kubernetes-PF-FlowSchema-UID and X-Kubernetes-PF-PriorityLevel-UID. You can use them to see where requests go.
E.g., let’s make a request to the API from the Cilium agent’s service account:
TOKEN=$(kubectl -n d8-cni-cilium get secrets agent-token-45s7n -o json | jq -r .data.token | base64 -d)
curl https://127.0.0.1:6445/apis/cilium.io/v2/ciliumclusterwidenetworkpolicies?limit=500 -X GET --header "Authorization: Bearer $TOKEN" -k -I
HTTP/2 200
audit-id: 4f647505-8581-4a99-8e4c-f3f4322f79fe
cache-control: no-cache, private
content-type: application/json
x-kubernetes-pf-flowschema-uid: 7f0afa35-07c3-4601-b92c-dfe7e74780f8
x-kubernetes-pf-prioritylevel-uid: df8f409a-ebe7-4d54-9f21-1f2a6bee2e81
content-length: 173
date: Sun, 26 Mar 2023 17:45:02 GMT
kubectl get flowschemas -o custom-columns="uid:{metadata.uid},name:{metadata.name}" | grep 7f0afa35-07c3-4601-b92c-dfe7e74780f8
7f0afa35-07c3-4601-b92c-dfe7e74780f8 d8-serviceaccounts
kubectl get prioritylevelconfiguration -o custom-columns="uid:{metadata.uid},name:{metadata.name}" | grep df8f409a-ebe7-4d54-9f21-1f2a6bee2e81
df8f409a-ebe7-4d54-9f21-1f2a6bee2e81 d8-serviceaccountsThe output shows that the request belongs to the d8-serviceaccounts FlowSchema and the d8-serviceaccounts PriorityLevelConfiguration.
Metrics to keep an eye on
The Kubernetes API provides several useful metrics to keep an eye on:
Apiserver_flowcontrol_rejected_requests_total: the total quantity of rejected requests.Apiserver_current_inqueue_requests: the current quantity of requests in the queue.Apiserver_flowcontrol_request_execution_seconds: the request execution time.
Some of the debug endpoints may also be helpful in obtaining useful information:
kubectl get --raw /debug/api_priority_and_fairness/dump_priority_levels
PriorityLevelName, ActiveQueues, IsIdle, IsQuiescing, WaitingRequests, ExecutingRequests
system, 0, true, false, 0, 0
workload-high, 0, true, false, 0, 0
catch-all, 0, true, false, 0, 0
exempt, <none>, <none>, <none>, <none>, <none>
d8-serviceaccounts, 0, true, false, 0, 0
deckhouse-pod, 0, true, false, 0, 0
node-high, 0, true, false, 0, 0
global-default, 0, true, false, 0, 0
leader-election, 0, true, false, 0, 0
workload-low, 0, true, false, 0, 0
kubectl get --raw /debug/api_priority_and_fairness/dump_queues
PriorityLevelName, Index, PendingRequests, ExecutingRequests, SeatsInUse, NextDispatchR, InitialSeatsSum, MaxSeatsSum, TotalWorkSum
exempt, <none>, <none>, <none>, <none>, <none>, <none>, <none>, <none>
d8-serviceaccounts, 0, 0, 0, 0, 71194.55330547ss, 0, 0, 0.00000000ss
d8-serviceaccounts, 1, 0, 0, 0, 71195.15951496ss, 0, 0, 0.00000000ss
...
global-default, 125, 0, 0, 0, 0.00000000ss, 0, 0, 0.00000000ss
global-default, 126, 0, 0, 0, 0.00000000ss, 0, 0, 0.00000000ss
global-default, 127, 0, 0, 0, 0.00000000ss, 0, 0, 0.00000000ssConclusion
We ended up solving our problem by setting up request queue management. It’s important to note that was not the only such case we experienced in our practice. After several occasions requiring to limit API requests, we made an APF configuration an essential part of our Kubernetes platform. Leveraging it helps us and our clients to reduce the number of API congestion issues in large, high-load Kubernetes clusters.
If you too have encountered similar issues in your practice and have discovered other ways to resolve them, please share your experiences in the comments.

Hello, I wanna thank you for this amazing blog and explanation. I have a question, how do I simulate the same scenario with your cilium pods crashing the api server, that would be a lot of help!!
Very helpful
Dear Team,First of all Kudo’s to your efforts, what an amazing share!!! I have a quick question if you can answer.I would like to know more in the context of how did you figure out that the cilium pods are sending the LIST requests to api server? Is there anyway we can see it from either cilium agent pod or api server pod? i tried figuring out but couldn’t find more info. Any help/reply would be greatly appreciated.By the way i am a fan of these blog articles. i keep following them regularly. RegardsKrishna
Hi Krishna, and thank you very much for your kind feedback!
Regarding your question:
apiserver_request_total{verb=~"LIST", instance=~".*:.*", resource=~".*"}in Prometheus to group requests by instances and resources. There, we discovered that many LIST requests originated from Cilium Network Policies.{"kind":"Event","apiVersion":"audit.k8s.io/v1","level":"Metadata","auditID":"...","stage":"ResponseComplete","requestURI":"/api/v1/namespaces/kube-system/configmaps?resourceVersion=0\u0026resourceVersionMatch=NotOlderThan","verb":"list","user":{"username":"system:serviceaccount:d8-system:deckhouse","uid":"...","groups":["system:serviceaccounts","system:serviceaccounts:d8-system","system:authenticated"],"extra":{"authentication.kubernetes.io/pod-name":["..."],"authentication.kubernetes.io/pod-uid":["..."]}},"sourceIPs":["192.168.199.91"],"userAgent":"deckhouse-controller/v0.0.0 (linux/amd64) kubernetes/$Format","objectRef":{"resource":"configmaps","namespace":"kube-system","apiVersion":"v1"},"responseStatus":{"metadata":{},"code":200},"requestReceivedTimestamp":"2024-01-17T15:30:12.396430Z","stageTimestamp":"2024-01-17T15:30:12.397651Z","annotations":{"authorization.k8s.io/decision":"allow","authorization.k8s.io/reason":"RBAC: allowed by ClusterRoleBinding \"deckhouse\" of ClusterRole \"cluster-admin\" to ServiceAccount \"deckhouse/d8-system\""}}Hope it helps!
Thank you so much for your reply. Let me go back and investigate.