 SRE as a Service
SRE as a Service DevOps as a Service
DevOps as a Service Cloud & Kubernetes migration
Cloud & Kubernetes migration Infrastructure & CI/CD audit
Infrastructure & CI/CD audit R&D and technology consulting
R&D and technology consulting Kubernetes support
Kubernetes support Solution for SaaS
Solution for SaaS All services
All services

Databases in Docker and Kubernetes have been a long-standing issue discussed in the community for years. The quick and general answer to this question is that you can run stateful apps in K8s, but extra attention and consideration are essential to end up with a decent outcome.
In this article, we will explore how stateful apps work in Kubernetes and what you should consider before and while running your stateful components in K8s. To make it even more practical, we will cover several well-known K8s operators to tackle your ClickHouse, Redis, Kafka, PostgreSQL, and MySQL instances.
Let’s start by reviewing Kubernetes’s background and why stateful workloads came into play.
Brief history of Kubernetes and its stateful support
Origins of Kubernetes
In the mid-2000s, microservice architecture in software engineering took off. This created a need for a new technology base, as it was extremely inconvenient to run microservices and manage them using the tools that had been around at that time. Containers ended up coming to the rescue.
Yet, this eventually gave rise to a new challenge: the scale and number of containers grew at a dramatic pace, revealing an urgent need for new orchestration tools. Google responded by creating its Borg workload orchestrator in 2003. It was based on Google’s own proprietary container technology (or what appeared to be).
The years that followed yielded even more container orchestration solutions, such as LXC or OpenVZ, but none of them was ever adopted en masse. In 2013, Docker came onto the scene with its innovative containerization ecosystem. Google recognized the promising potential of the new solution and created a successor to Borg — Kubernetes — based on those Docker containers.
The sparkling beauty of the orchestrator
Despite Kubernetes being treated by some engineers as an excessive, unnecessary hassle, its adoption started to sprout. It was obvious that microservices, Docker containers, and Kubernetes were beneficial to the future of software development. The 2014 year ushered in a steady rise in the popularity of containerization and orchestrators, and by 2018, Kubernetes had become the de facto industry standard.
Looking at Kubernetes in its first years, we realized its potential, feeling that it could make our engineering lives easier by providing a scalable, fault-tolerant infrastructure, complete with load balancing, monitoring, etc. Kubernetes also relieved us of the biggest pain all engineers have to deal with by enabling unification, as it provided a common interface and API.
Early-stage Kubernetes paved the way for complex, flexible mechanisms to deliver software releases. It was able to distribute load and manage multiple containers, featuring self-healing and versatile resource utilization. However, at the time, all of these wonderful things were applicable only to stateless applications.
Stateful needs
Over time, software developers’ demand for dynamic environments increased significantly. This approach assumes many copies of software are created (for each Git branch) where you can easily test your currently developed software version. Since almost every application relies on databases and queues, all those environments had to support stateful components.
Cloud Native stateful applications were also evolving. In these applications, the issues of fault tolerance and scaling have existed since the emergence of clouds. The trend towards multi-zone and cross-data center installations only underscored their significance even further.
In short, Kubernetes needed to support stateful workloads. Thankfully, the developers were attentive to the community’s requests. In a mere 1.5-2 years after the initial release, in Kubernetes 1.3, PetSet (later renamed to StatefulSet) was introduced. Years later, in 2019, the Custom Resource Definitions (CRDs) arrived, allowing you to flexibly implement various application management logic that was more complex than just managing a set of instances in a Kubernetes Deployment.
Well, that’s enough history. Let’s move on to more practical matters with stateful workloads in Kubernetes!
Evaluating your stateful components
The popular opinion about Kubernetes is that all you need to do is place YAML files next to your application, and it will work — it’s a no-brainer. However, when it comes to stateful, you still need to do some analysis to decide whether you even want to run this component in Kubernetes.
There are several criteria to help you evaluate a component before running it in K8s:
- Performance: Is it enough? Is the network or disk performance a limiting factor?
- Data safety: This one’s more a matter of privacy: can the database be hosted along with the cluster?
- Fault tolerance: Can the application/component/database scale, run in two replicas, and achieve the desired SLA level?
- Backups: Backups are often created in a centralized fashion, so if you run some part of your app in Kubernetes, it is not always possible to back it up.
- Reasonability: Say you just want to deploy and use some database. Do you really need to follow the latest trends for that? In many cases, Ansible scripts will do just fine. On the other hand, if you need to repeat this hundreds and thousands of times in some dev environments, then it makes sense to sort things out and run it in Kubernetes.
How stateful apps work in Kubernetes
Let’s start with a general example. Say there is a Pod that requires a Volume to store data:
- To gain access to it, this Pod sends a PersistentVolumeClaim (PVC) to a StorageClass (SC).
- Then, the StorageClass issues a PersistentVolume (PV) to that Pod.
- Next, Kubernetes simply heads to the Storage, allocates a partition there, and mounts it to the Pod.
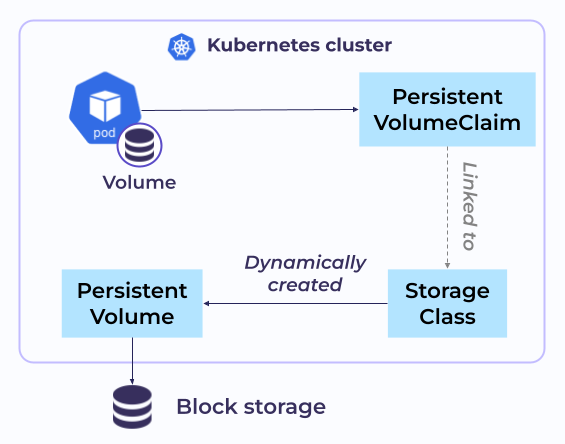
Now, the Pod can read data from the Volume and write data to it. The best part is that if the Pod gets restarted, the data will still be there.
Okay, we’re ready to make things a bit more complicated. Say there’s a PostgreSQL database that you want to host in a Kubernetes cluster. To do so, you’ll need to mount the datadir that PostgreSQL uses in the StatefulSet manifest.
kubectl get sts psql -o yaml
...
volumeMounts:
- mountPath: /var/lib/postgresql
name: pgdata
...At that point, you’ll need to repeat this N times: in all your environments for developers, and then on the stage, pre-prod, and finally, the production environments. A month later, you’ll discover that the cloud costs are rising. Turns out that the disks are piling up.
To illustrate what’s going on here, let’s use Helm (which manages software releases) as an example. When purging a release, Helm only deletes the StatefulSet, while the PVCs and PVs that were created based on it remain:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: psql
spec:
...
volumeClaimTemplates:
- metadata:
name: pgdata
spec:
resources:
requests:
storage: 1Gi
...To prevent this, we can use a Volume that has been mounted in a dedicated PersistentVolumeClaim in a separate manifest instead of a volumeMount. In this case, the PVC will be part of the Helm release and will be deleted along with the review environment.
apiVersion: apps/v1kind: StatefulSetMetadata: name: psqlspec: spec:... volumes: - name: pgdata persistentVolumeClaim: claimName: pgdata...apiVersion: v1kind: PersistentVolumeClaimMetadata: name: pgdataspec: resources: requests: storage: 1Gi...helm uninstall --debug psql-test -n testuninstall.go:95: [debug] uninstall: Deleting psql-test
client.go:310: [debug] Starting delete for "psql-test" Service
client.go:310: [debug] Starting delete for "psql" StatefulSet
client.go:310: [debug] Starting delete for "pgdata" PersistentVolumeClaimThe PVC is gone, but the PVs are still there:
kubectl get pv
NAME CAPACITY RECLAIM POLICY STATUS
pvc-15d571eb-415a-4968-afb7-4f15cd0f5bef 2Gi Retain Released
pvc-2660b9bd-65f0-4bf9-9857-4e036f6cb265 1Gi Retain Released
pvc-2e428234-f7f6-448e-8913-cd74f9d3a451 1Gi Retain Released
pvc-334ac272-47f1-4dcf-8fa9-f74b3c848874 2Gi Retain Released
pvc-33c9cf2d-64a9-49ea-babe-1ac9c3045524 1Gi Retain Released
pvc-3a93b9f6-866e-4947-b60f-09e75b1d899f 2Gi Retain ReleasedThis is due to the reclaimPolicy.
Reclaim policy in a storage class
This policy is inherited from the StorageClass via which the PersistentVolume was provisioned. By default, it is set to Delete.
kubectl get sc ssd -oyaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: ssd
...
reclaimPolicy: DeleteIn this case, the PV will be deleted once the PVC has released it. The downside is that you can end up losing important data as a result.
The alternative value of reclaimPolicy is Retain.
kubectl get sc ssd -oyaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: ssd
...
reclaimPolicy: RetainWith such a reclaimPolicy, the PV will switch to Released, and if you remove the PVC release, the PV will retain Released status. On top of that, if you then manually remove these PVs from the cluster, they will still remain in the cloud. This is to ensure that vital data is never lost.
Reusing persistent volumes
Let’s talk about the possibility of data loss in a bit greater detail. As you may recall, we are running Postgres in Kubernetes, and everything is now running in production. Suppose the developers decided that the dev environment has been out of use for a while and can just be removed:
kubectl delete ns -n dev --allAs a result of this command, they not only deleted their own dev environment but the entire cluster — only kube-system and default remained. This seems like a funny situation, but we’ve had to deal with this numerous times. In any case, it’s a perfect time to retrieve the aforementioned backups.
Fortunately, a PV in Released status can be reused. The PV keeps information about the PVC from which it originated, so you have to clean up the claimRef.
apiVersion: v1
kind: PersistentVolume
metadata:
name: pvc-480c58d4-d871-4e68-b908-1f475a1b5f9c
spec:
...
claimRef:
apiVersion: v1
kind: PersistentVolumeClaim
name: psql-pgdata-0
namespace: production
persistentVolumeReclaimPolicy: Retain
...The PV then assumes Available status and can be reused:
$ kubectl -n test get pv pv-test
NAME CAPACITY RECLAIM POLICY STATUS CLAIM
pv-test 1Gi Retain Released test/pgdata-psql-0
$ kubectl -n test patch pv pv-test -p
'{"spec":{"claimRef": null}}'
persistentvolume/pv-test patched
$ kubectl get pv get pv pv-test
NAME CAPACITY RECLAIM POLICY STATUS CLAIM
pv-test 1Gi Retain AvailableIf you create a PVC that matches the StorageClass and is of a suitable size, the PV will be mounted.
$ kubectl -n test scale psql web --replicas 1
statefulset.apps/psql scaled
$ kubectl -n test get pv pv-test
NAME CAPACITY RECLAIM POLICY STATUS CLAIM
pv-test 1Gi Retain Bound test/pgdata-psql-0It will be mounted even if the PVC has less volume as long as it meets the requirements.
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: psql
spec:
...
volumeClaimTemplates:
- metadata:
name: pgdata
spec:
resources:
requests:
storage: 500Mi
...Replacing a storage class
Now, let’s tackle replacing the StorageClass in the StatefulSet. Earlier we said that you have to evaluate the performance of your stateful workloads prior to running them in Kubernetes. Unfortunately, that’s easier said than done — it all comes down to the disks’ performance.
The obvious solution would be switching to SSD and asking your Kubernetes operators to create a new StorageClass — you’ll need to replace it. However, attempting to change the StorageClass right in the StatefulSet manifest will result in an error:
Error: UPGRADE FAILED: cannot patch "psql" with kind StatefulSet: StatefulSet.apps "psql" is invalid: spec: Forbidden: updates to statefulset spec for fields other than 'replicas', 'template', 'updateStrategy', 'persistentVolumeClaimRetentionPolicy' and 'minReadySeconds' are forbiddenThis is because most fields in the StatefulSet manifest are immutable.
To modify the StorageClass, you can delete the Postgres StatefulSet that is running in the production via the --cascade=orphan option.
$ kubectl -n test delete sts psql --cascade=orphan
statefulset.apps "psql" deletedThe best part is that Pods running as part of this StatefulSet will stay running. Nothing will happen to them.
Now, all you need to do is deploy the new StorageClass into a StatefulSet. Once the StatefulSet scales to multiple new replicas, the new Pods will start using the new StorageClass.
$ kubectl -n test scale sts psql --replicas 2
statefulset.apps/psql scaled
$ kubectl -n test get pvc
NAME STATUS VOLUME CAPACITY STORAGECLASS AGE
psql-0 Bound pvc-1 1Gi old 1h
psql-1 Bound pvc-2 1Gi new 5sNote, however, that Kubernetes does not carry out any auto-migration in this case. You have to do it manually, or the application must be able to do it.
Persistent volume access modes
Finally, understanding PersistentVolume access modes is also essential. They can be briefly illustrated as follows*:
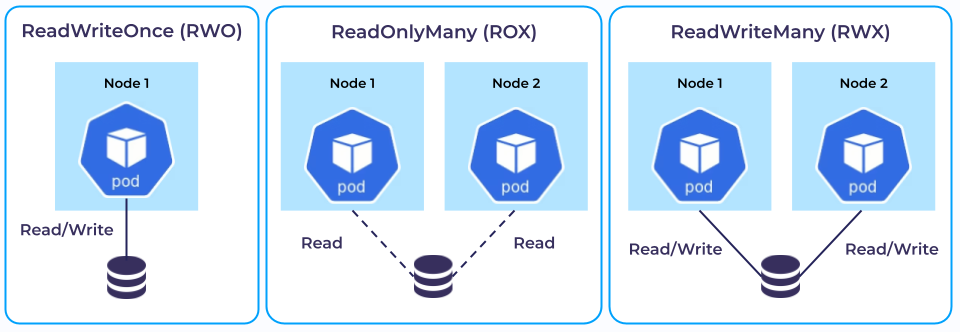
Here:
- RWO is the most common one: there is a consumer that reads and writes to its Volume. This can be done in any cloud that has some sort of storage.
- ROX implies that reads are made from different Pods on different nodes. Unlike the previous mode, this one is not universal.
- RWX is the most complex situation where reads/writes are performed from different nodes to a single Volume.
* In Kubernetes v1.29, the RWOP (ReadWriteOncePod) mode was also declared stable. With it, a volume can be mounted as read-write by a single Pod.
Well, experienced system administrators might recommend using good ol’ NFS… But weren’t we building fault-tolerant infrastructure? If now we are supposed to move all our persistent data to NFS, which is not fault-tolerant, there’s not much sense.
The Twelve-Factor App manifesto by Heroku recommends using S3 to store static files. For this approach, you will need some new libraries while rewriting the legacy code. This is not always feasible, and you might end up resorting to workarounds, such as s3fs.
s3fs uses the widely known FUSE (Filesystem in Userspace) under the hood. This means that each read-write operation requires three context switches. Given that, you can’t get a high IOPS: if you host a database that way, you’ll hit the performance limit almost immediately. So you can use S3 for static files, while for databases, you’d be better off using CephFS at least.
When operators come into play
As the number of primitives and options grows, you have to keep and consider more and more information in your head, thus increasing the risk of mistakes. To minimize this issue, eventually, you will want to automate everything.
Here’s an example. Suppose you need to run a ClickHouse cluster consisting of two replicas and one shard in Kubernetes. You will need to define two StatefulSets for replicas right from the start. It is becoming a distributed system, and we’ll need ZooKeeper to coordinate the actions. Now it looks like it would be a big chore to describe and tie it all together.
$ kubectl -n clickhouse-prod get sts
NAME READY
chi-0-0 1/1
chi-0-1 1/1
zookeeper 3/3
$ kubectl -n clickhouse-prod get po
NAME READY STATUS
chi-0-0-0 1/1 Running
chi-0-1-0 1/1 Running
zookeeper-0 1/1 Running
zookeeper-1 1/1 Running
zookeeper-2 1/1 RunningLuckily, in fact, you can do it in just one YAML file! Simply specify the number of replicas and shards that you want, and Kubernetes will deploy them all “automagically.” Here’s your manifest:
apiVersion: clickhouse.altinity.com/v1
kind: ClickHouseInstallation
metadata:
name: clickhouse
namespace: clickhouse-prod
spec:
configuration:
clusters:
- layout:
replicasCount: 2
shardsCount: 1
name: production
...… and the outcome of applying it:
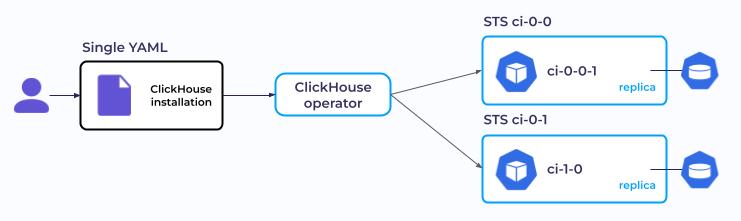
As you could have guessed already, this can be done with the help of Kubernetes operators. They leverage new manifests, which are then used to create custom resources (CRs) in K8s that you can easily manage.
Operators are essentially implementations of different means of software control. There is a handy framework available that allows you to assess operator maturity.

- Level 1 operators are only good for basic app provisioning and configurations.
- Level 2 is capable of performing smooth software updates.
- Level 3 ensures full application lifecycle management, including backups and disaster recovery.
- Level 4 operators come with comprehensive monitoring.
- The “autopilot” level means that all you do is adjust the parameters while the operator makes all the necessary changes on its own.
It’s time to list the operators we use to run stateful workloads in Kubernetes and the pitfalls we encountered when using them.
The operators we use for stateful apps
For each operator, we will provide the number of GitHub stars, open/closed GitHub issues, and their capability level (according to the framework above).
Altinity Kubernetes Operator for ClickHouse
- GitHub
- GH stars: ~1.8k
- Open/closed issues: 113/607
- Capabilities: 3
We have been happily using the ClickHouse operator by Altinity for years. It is capable of managing sharding and scaling right out of the box — just set the number of replicas.
In addition to the main operator features listed in its official description, I’d like to highlight one particularly helpful functionality. In most cases, you can only deploy a cluster-wide operator that subscribes to all custom resources in the cluster. So, for example, if a cluster has both dev and production environments, you can’t limit the operator update to the dev environment to test/try out its new version there.
But if the operator can keep track of specific namespaces, you can specify that a new version should be installed in the dev namespace while the old one will continue to run in production. The Altinity operator’s latest versions can do this.
There’s one more interesting particularity, which stems from the first one. Sometimes, operators subscribe to custom resources and process them sequentially, one by one, i.e., in a single queue. Thus, for example, if an installation in the dev environment fails while the production runs out of space at the same moment, you add custom resources and enlarge the disk. In fact, the operator can provision a larger disk in the cloud and make everything run smoothly, but now it’s busy watching the dev installation failing. An operator can’t do anything if it has a single thread and uses a single queue. You can address that issue by deploying two operators, one for each namespace.
Redis Operator by Spotahome
- GitHub
- GH stars: ~1.5k
- Capabilities: 2
- Open/closed issues: 4/332
We have been using the Redis operator by Spotahome for a long time now, and you might have read this article about its specific issue before.
Now imagine a typical situation: there was a sudden increase in traffic, and the Redis replica ran out of disk space or RAM and failed. You need to deploy it again. The drawback of this operator is that its probes are hardcoded. So, the replica tries to get deployed and fails due to a probe. In this case, you have to turn off the operator (scale it to zero), deploy the replica, and turn it back on. In other words, you need an operator for an operator.
On top of that, since Redis is single-threaded, it frequently underperforms. Oftentimes, we simply replace the Redis binary with KeyDB in the image. The Spotahome operator doesn’t care what it runs, which means our custom image will work perfectly.
Redis Operator by Opstree Solutions
- GitHub
- GH stars: ~0.7k
- Capabilities: 1
- Open/closed issues: 87/370
This operator is newer and less mature than the previous one. It’s only included on our list because we once used it to create a multi-data center Redis installation, and the operator by Spotahome doesn’t support TLS.
NB: It’s worth noting that almost no operators can create a Redis cluster. Fortunately, our clients usually don’t need it — we use a regular Redis failover on Sentinel, and that does the trick.
Strimzi Kafka operator
This operator by Strimzi, a CNCF incubating project, is well-written, fairly mature, and popular in the CNCF community.
Kafka was designed as a Cloud Native application right from the start — therefore, it scales easily. However, you have to keep an eye on the expiration date of the certificates.
This operator is good at demonstrating how developers can add additional abstraction levels when they lack something in existing Kubernetes API objects. As you know, Pods in StatefulSet are numbered from zero to infinity. The Strimzi developers used broker IDs to bind to Pod IDs, but the disadvantage of this approach is that you can’t delete brokers from the middle.
Therefore, they rewrote the StatefulSet primitive and created their own StrimziPodSet. Basically, it’s a set of Pods that allow you to dynamically change certain resources with their broker IDs. This proposal adds flexibility, but the payoff is the introduction of a new abstraction. When the node where the Pod is running goes down, you know how the StatefulSet will behave: it will stop if the disk is local, or it will move to another location. But you can’t predict how StrimziPodSet will behave: the documentation sometimes isn’t really helpful, so you have to read the code.
Postgres Operator by Zalando
The issue of deploying relational databases in Kubernetes is inherently controversial, but we’ve been successful in doing it with PostgreSQL. In most cases, we use the operator by Zalando, which comes bundled with Patroni. The latter performs well when we run both Patroni and PostgreSQL in the cluster, as well as when we use PostgreSQL on virtual machines or hardware outside the cluster and only Patroni runs in the cluster.
The excellent approach to performing in-place PostgreSQL updates is worth noting. The image of a particular operator version includes several consecutive versions of PgSQL. This way, you can update the PostgreSQL version on the fly and perform all the necessary migrations without restarting the containers. However, the PostgreSQL versions are always tied to specific versions of the operator. Therefore, if you use an operator and a new version of a component is released, you cannot update it right away. You have to wait for the new version to be supported by the operator. Sometimes, the operator also is tied to a specific Kubernetes version. In that case, if you have an older version for some reason (e.g., due to the deprecated API), you will have to wait, too.
The drawback of this operator is that the number of WALs is hardcoded at 8. Since we capture PostgreSQL backups using pg_basebackup, we just couldn’t keep up with the pace of the backups. It turned out that the operator’s developers used WAL-E in the past but have recently switched to WAL-G. We figured out how everything worked and just reimplemented our backups.
CloudNativePG
This operator is quite new and is definitely a rising star in the space. Originally created by EDB, it aims to be community-governed and was even proposed to the CNCF Sandbox (however, for some reason, it hasn’t made it yet).
CNPG controls Pods directly, which is not always good for auto-recovery: when a Pod goes down, you have to interfere with the operator because it fails to recover properly (it switches to a replica).
Previously, we have provided a detailed overview of CNPG, including its comparison to other well-known Kubernetes operators for PostgreSQL, in this article.
MySQL Operator by Bitpoke
Over the past year, we’ve tried almost 20 MySQL operators, but most of them are tailored for group replication, which was introduced in MySQL 8. However, we also have to support older versions of MySQL, namely 5.6 and 5.7. On top of that, sometimes, we need simple master-slave setups since buying another huge server for the database is not always on our customers’ to-do lists.
We reviewed all the candidates and opted for the solution from Bitpoke, a company aiming to democratize WordPress hosting by bringing it to Kubernetes. This operator proves to fit our needs, and recently, we rolled out our first production environment running with this operator — before that, it only worked in dev environments.
However, it currently has some shortcomings typical for early-stage projects. For example, it doesn’t know how to make binlog backups since it doesn’t have PITR. We’re using workarounds to overcome these issues.
Summary on using K8s operators
Let’s summarize our experience with using operators to run stateful apps in Kubernetes. Here are the advantages:
- Operators lower the entry threshold.
- Depending on the maturity level, they automate routine operations as well as some phases of the application lifecycle.
- They unify approaches: if there’s an operator, you can be certain that everything is uniform and you don’t have to worry about maintaining and updating a bunch of component charts.
The main disadvantage is that operators add abstraction levels that you have to deal with. Sometimes, you have to even analyze their code to understand why they do what they do.
Keep in mind that it’s the users who make the operators more mature. That’s why it’s essential to leave feedback for these projects to evolve and improve.
Takeaways
Before running stateful components in Kubernetes, you need to evaluate the infrastructure’s capabilities and overall reasonability. Running stateful in Kubernetes is not a silver bullet. Sometimes, it makes sense to use existing (i.e. out-of-Kubernetes) solutions and stick to proven practices.
Running stateful in Kubernetes relies on well-known approaches to building infrastructure but has its own peculiarities and subtleties. You have to keep this in mind when designing this kind of architecture.
Operators help you automate certain stages of the stateful lifecycle. The selection of them is rather broad: you can find at least a few of them for any task. However, it might turn out that the chosen operator lacks some of the features you need, so you will have to either swap the old operator for a new one or refine the one you are using.
Nowadays, Kubernetes is equally capable of handling both stateless and stateful applications. The ease of use of stateful components in an application often depends on the vendor providing Kubernetes services, but if you look at the big picture, Kubernetes is evolving, and stateful in Kubernetes is the way to go.

Comments