

Adapty Tech Inc. recently embarked on a journey of cloud transformation with Palark, migrating its infrastructure away from AWS managed services and onto the Kubernetes cluster. This move not only freed them from vendor dependence but also resulted in significant savings — a 50% reduction to their existing costs! Added benefits included increased scalability for their applications as well as optimized performance.
This article explores some of the elements that helped to achieve these savings, discusses the challenges encountered during the migration as well as Palark’s role in the process, and highlights the benefits of Kubernetization.
Preliminary notes
This article should not be regarded as a technical guide but rather as a business case. The technical details it covers are meant to help our readers take a look at the big picture from a business standpoint.
Although we do provide some figures, the non-disclosure agreement does not allow us to disclose Adapty’s specific budget totals. For that reason, when it comes to the economic benefits of migration, we will only be giving relative values.
Briefly about the service
Adapty is a service developed to help app developers maximize their subscription revenue. It provides various tools such as paywall A/B testing for better conversion of users into paid subscribers and an interactive dashboard with key performance metrics. Adapty also offers an easy-to-use SDK allowing merchants to quickly enable in-app purchases functionality.
Adapty’s customers are mostly mobile app developers. Some apps boast millions of subscribers. In total, Adapty serves over 120 million app users. As the number of customers grows, the traffic grows along with it. As you know, traffic is not free, and its cost in cloud environments may depend not only on the number of end-users but also on a variety of other factors (the way services interact with each other, etc.). In the case of Adapty, the traffic price tag was rising so rapidly that the company decided to rethink the whole architecture.
Reasons for abandoning the original architecture
1. Rising traffic costs
Adapty initially settled on AWS for its infrastructure needs. The team was satisfied with the preliminary monthly cost estimate obtained via the Amazon calculator. However, this calculation only included fixed payments for virtual machines (VMs) and managed services. Non-fixed payments — including traffic costs — were not factored into the estimate.
It turned out that the biggest problem was the outbound traffic — the kind of data that Adapty’s servers send to customers’ mobile apps (Data Transfer Out from Amazon EC2 to the Internet). The growth of their customer base led to a traffic increase by hundreds of terabytes per month. As a result, prior to the migration, more than 60% of the total bill for AWS services bill was from traffic.
2. High IOPS costs
The second major expense category was IOPS charges. High IOPS measurements are crucial for the Adapty database, and you have to pay for the extra IOPS.
3. Vendor lock-in
The entire Adapty infrastructure was based on Amazon managed services such as Elastic Container Service (ECS) for container orchestration), Relational Database Service (RDS) as a database, Application Load Balancer, CloudWatch for logging, ElastiCache as Redis, and last but not least, Kinesis-Lambda-S3 bundle for analytics. All these services are tied to Amazon. You cannot migrate or replicate them. In other words, Adapty became dependent on a single platform. Under such conditions, it was impossible to quickly migrate to a different infrastructure in the event that problems were to occur.
4. Not enough features (within the managed services)
Most managed AWS services are easy to set up and maintain. The downside of convenience is limited functionality. This applies, for example, to the ECS container orchestrator, which is much less capable than Kubernetes, the de facto industry standard. An Amazon-built cloud version of PostgreSQL (RDS) has its own tiny caveat: only another RDS instance can be a streaming replica for the existing DB.
To eliminate these problems, we migrated the infrastructure to self-hosted (not managed) Kubernetes and replaced the cloud services with their Open Source counterparts. At the same time, we switched to the Google Cloud Platform. However, it’s important to note that it was not the new provider but the move to K8s and other self-hosted solutions made the savings possible (more details provided below).
Migration and challenges
Our SRE/DevOps team helped Adapty migrate the infrastructure and, upon completion, proceeded to support it. However, not everything went according to plan…
The bulk of the work was completed in about three weeks. Thereafter, we had to set up, optimize, and stabilize some services after the move, and that process added another three weeks to the ETA.
Here is a rough scheme of our preparatory activities:
- Deploy a Kubernetes cluster on GCP instances.
- Plan database migration (when and how).
- Draft a migration plan for the load balancer and traffic switching.
- Make necessary changes to the CI/CD process.
- Plan the migration of the applications.
Now, let’s discuss the primary obstacles we encountered during the move.
Database
One of the critical limitations of Amazon RDS is that you cannot physically replicate the database to another cloud or to your own VM. That is, we had to compile the whole database from scratch.
The vast database size (about 1.3 TB) rendered our task more challenging. In addition, not only were database updates rather frequent and large (up to 1 TB of data per hour), but on top of that, as part of the migration, we also had to upgrade PostgreSQL from v12 to version 13.
As a result, the database migration took place in several stages and proved to be the most time-consuming stage of the project. In total, we spent more than two weeks on the DB migration alone.
Traffic balancing
AWS had used Application Load Balancer for rate limiting and returning an HTTP 429 status code. However, Google’s Cloud Load Balancer (CLB) works differently and has its own unique set of features. After switching to CLB, we configured HTTPS terminating and filtering similarly to how they’re done in AWS. However, it took us a lot of time to configure CLB properly since it is much more complicated than ALB. At one point, we even had to turn to Google engineers for help.
Logging
We used a system based on a proven Open Source stack (Elasticsearch, Logstash, Kibana) as an alternative to CloudWatch. However, we had to heavily customize the ELK stack to implement the same functionality that Adapty had in CloudWatch. The fine-tuning continued for some time after the migration was complete.
Unceasing Dev & Ops collaboration
During the migration, together with the client in our Slack chats, we took a deep dive into the asynchronous messaging bus implementation and solved problems with atypical HTTPS termination and HTTP header processing. We investigated the database-related issues and tested various solutions with the developers. Sometimes, this resulted in new challenges we successfully addressed. Some of them had to be solved immediately (including at night). In such cases, both teams worked in unison, communicating via Google Meet.
The results of the migration
When everything was done, only the analytics service (Kinesis + Lambda + S3) was left in AWS. All the other production services were deployed in the GCP cloud — mainly as Open Source solutions.
Meanwhile, it is important to emphasize that the Adapty infrastructure started using regular virtual machines hosted by Google. Kubernetes is running on top of them and, what’s more important, is not tied to any specific cloud provider services. Deckhouse, being a CNCF-certified K8s distribution that runs on any infrastructure, made it possible. You can run it on instances of any cloud provider as well as on your own OpenStack installation or bare metal servers.
The only thing that ties Adapty’s current infrastructure to a specific cloud provider is Google Cloud Load Balancer. It receives client traffic and routes it to the Kubernetes Ingress. However, this doesn’t seem to pose much of a problem since you can quickly eliminate vendor lock-in by deploying the NGINX balancer on a virtual machine or a dedicated server if you need it.
We still have to pay for the virtual machines, IOPS, and traffic, but the total is now noticeably lower.
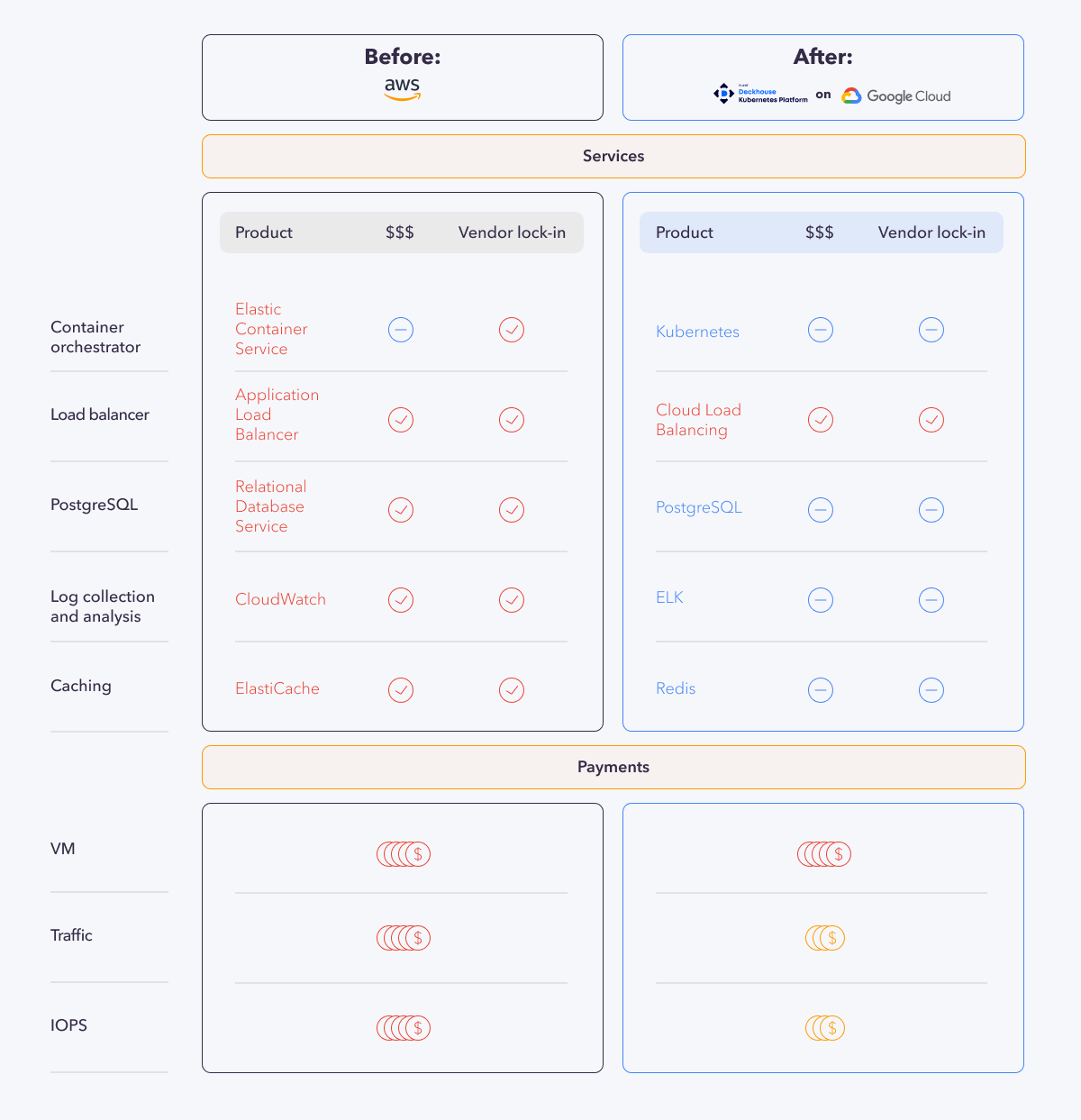
The figures below show the cost reductions for each category:
- traffic — 60%;
- database — 50%;
- logging — 40%;
- caching — 30%.
It’s essential to anticipate the case of traffic. This decrease happened due to architecture optimization and migration to Kubernetes, not because the new cloud provider had cheaper traffic. In particular, we managed to eliminate the “internal” traffic between AWS regions by removing the redundant full mesh between the API, PgBouncer, and the database.
As for IOPS, we managed to get rid of the provisioned IOPS by switching to large SSD disks for the database (about 30 IOPS allocated to each gigabyte, which renders the performance similar). Other savings were achieved by migrating to Open Source analogs.
Meanwhile, it’s worth noting that the cost of maintaining the infrastructure has remained the same.
As a result, the overall cloud infrastructure costs were reduced by about 50%.
Why was Palark selected to carry out the migration in the first place? Adapty does not consider server administration to be the company’s core competence, nor does it see this as a business advantage. It makes sense for Adapty to outsource DevOps-related tasks to those who are good at it and focus on the core product instead:
If we tried to migrate to Kubernetes ourselves, we would have spent considerably more time figuring out how it works and how to use it properly. Moreover, we had no experience setting up monitoring, while Palark had a ready-made monitoring system capable of replacing CloudWatch. Using it, we quickly found several inefficient queries that put a heavy load on the database and rewrote them, thereby reducing the burden. For some metrics, we didn’t even think they had to be analyzed. But, as it turned out, that is important for Kubernetes.
Kirill Potekhin, CTO @ Adapty
The technical advantages of moving to K8s
Through this migration, Adapty got rid of vendor lock-ins for key services. With Adapty switching to self-hosted Kubernetes, its infrastructure has become independent of the IaaS provider: the cluster can easily be migrated to another cloud (including dedicated or bare metal servers). There are other advantages as well:
1. Autoscaling
In Adapty’s case, Deckhouse’s dynamic autoscaling came in handy. Our client sometimes experiences sudden traffic spikes: for example, the number of RPS can jump from an average of 2,000 to 30,000 — and then drop just as quickly. To handle such situations, dozens of backup application replicas were running on AWS virtual machines. Most of the time, these VMs were idle.
Now, K8s is configured to autoscale nodes and Pods dynamically (thanks to the node-manager module). Its machine-controller-manager provisions nodes in the selected cloud (AWS, GCP, and other cloud providers are supported). Additional Pods are deployed to these nodes as needed. In addition, the provisioned nodes can be put into standby mode to speed up the process even more.
The werf CI/CD tool has also contributed to the autoscaling process optimization. Adapty uses the HPA (Horizontal Pod Autoscaler) to control the number of Pods. This resulted in an unforeseen problem. Suppose that the number of replicas specified in the Deployment configuration is limited to 25 Pods and the application experiences a traffic spike. In that case, HPA increases the number of Pods to, say, 100. If you roll an update at that point, the number of Pods will be reset to 25, leading to service delays. We got around this problem by adding the replicas-on-creation annotation when deploying the application using werf and zeroing the replicas: N parameter in the Deployment.
Deckhouse provides similar automation for disks: it can provision them automatically. Suppose you need to deploy a database that requires persistent storage. You can provision it via the Deckhouse storage classes. To do so, you need just to specify the desired disk size and type in the YAML manifest. Speaking of disks, another handy Deckhouse feature is the ability to expand the PVC (PersistentVolumeClaim) in a cluster or YAML with subsequent redeployment.
2. Pod stability
Amazon’s ECS tasks (the equivalent of Pods in AWS) were prone to crashing due to a lack of memory and then could not restart afterwards. While the cause of the first problem could usually be identified, that wasn’t the case with the second one. Adapty had to develop a workaround script that ran every 30 seconds and checked for all the tasks, restarting the crashed ones. Switching to K8s has eliminated this problem. If some Pod crashes, Kubernetes restarts it, and you can find the cause of the problem using the standard K8s tools.
3. CI/CD
Implementing the CI/CD pipeline is easier in regular Kubernetes since it supports all industry-standard tools. In our case, we used werf (as you might expect). Obviously, it could have been any other tool you like or are familiar with.
The next steps
The next step in infrastructure and cost optimization is to move some services to bare metal servers in one of the local data centres. For example, the machines processing API requests (the destination for almost all traffic) are stateless: they do not store data and only execute code, so they are excellent candidates for migration to a low-cost data center. That way, you won’t have to pay for traffic at all. At the same time, you can leave critical infrastructure (such as a database) on GCP because Google provides a sufficient level of fault tolerance and availability.
By moving to Kubernetes, Adapty was able to decrease their spending by 50% while increasing the scalability and performance of the applications. If you’re looking for a way to save money on your cloud infrastructure, migrating to Kubernetes is a great option. Contact Palark today and see how we can help you make the switch!
UPDATE: Video
Following this article, we also made a video where our CTO, engineers, and Adapty’s CTO tell the story of this migration. Enjoy watching it!

Comments