 SRE as a Service
SRE as a Service DevOps as a Service
DevOps as a Service DevOps emergency
DevOps emergency Cloud & Kubernetes migration
Cloud & Kubernetes migration Infrastructure & CI/CD audit
Infrastructure & CI/CD audit R&D and technology consulting
R&D and technology consulting Kubernetes support
Kubernetes support Solution for SaaS
Solution for SaaS All services
All services

One of our customers needed their Amazon RDS database instances in Aurora managed service to scale automatically. Horizontal scaling is a basic feature that AWS provides on-demand. As for vertical scaling, it is currently not available. However, there are some tools you can use to implement it yourself, which is precisely what we did and covered in this manual, including the related code.
Before we start, let’s clarify the basics of scaling our resources in general:
- Horizontal scaling involves adding additional servers to distribute load and data between them. For databases, this means dividing the data up across different servers or database instances.
- Vertical scaling, on the other hand, involves augmenting the performance of an existing server by adding more CPUs, RAM, or disk space. For databases, this means improving the performance of the single server the database is running on. That’s the scaling type we are aiming for since Aurora for Postgres supports 1 writer instance only.
Let’s proceed to how we made it possible.
AWS tools we used
We decided to stick to the broad range of tools AWS offers and avoid adding any third-party dependencies where possible. Here are the components we ended up with:
- Amazon CloudWatch Alarms allow you to watch Amazon CloudWatch metrics and send notifications or make automatic changes to resources once the metrics cross certain thresholds.
- Amazon RDS Events (and Amazon RDS Event Subscription) is an events mechanism helping you to track Amazon RDS-related activities, such as creating, modifying, and deleting database instances, as well as other database management operations. You can subscribe to these events and receive relevant notifications via Amazon SNS (Simple Notification Service). Subscribers can customize which events trigger notifications and select the way they receive them (e.g., via email, SNS, or HTTP calls). However, there is no way to directly call a lambda function using RDS Event Subscription.
- Amazon Simple Notification Service (SNS) is a message delivery/sending service that allows notifications or messages to be sent out to microservices, distributed processing systems, and server-side applications, including lambda functions.
- AWS Lambda Functions allows you to run code in multiple languages (Python and Go, among others). It eliminates the need to deploy code or manage servers. Even better, it scales automatically based on the request volume.
Note: We could also have used the AWS Step Functions service to address some of our needs, but we managed to get by without it.
Implementing vertical autoscaling
Vertical scaling commences when a CloudWatch Alarm is triggered in the RDS cluster. This alarm is currently based on the CPU Load Average value and runs once it exceeds a certain predefined threshold (80%). Consider it more of an example since you can use any other metric for your trigger. Then the SNS invokes the first lambda function.
1. The Alarm function
Here’s how the Alarm lambda function works:
- First, it receives a CloudWatch Alarm;
- It then identifies which RDS cluster and which instance were the source of the alarm;
- Next, it performs some tests:
- It checks if there are any instances in the cluster that are being modified at the moment. This check is necessary in order to minimize the impact on the cluster: no more than one instance should be modified at any given time;
- It checks if any of the cluster instances have a
modifyingtag. This is to prevent modify requests from being processed by AWS for too long. The point is that tagging is instantaneous, whereas modifying requests can take several minutes to execute. Without the tag, this would cause the function to be invoked multiple times; - It checks whether enough time has passed since the last instance size change. To decide if we can perform a scaling now, the latest
modificationTimestamptag value in the cluster is compared with the current time minus a configurable cooldown period;
- If all the conditions are met, the function:
- identifies the types and sizes of instances in the cluster;
- performs scaling;
- sends out a notification of the results.
To perform scaling, this function features an algorithm for sizing and scaling the instance. Here is how it works:
- The algorithm compares the current instance size to the maximum possible one. There might be several instance families available to choose the value from; these options can be specified for each cluster manually using a variable;
- It then searches for all instances of the reader type. Next, it filters through them to find the smallest size instances. After randomly selecting one of those, it sends a request to increase its size to the size of the biggest existing instance in this cluster. The instance is tagged as
modifyingand with the current timestamp (modificationTimestamp); - If all instances in the cluster are of the same size, it sends a signal to a randomly selected reader to increase it to the size of the next possible instance type. For example, the t5xlarge instance may be scaled up to t5x2large;
- If all instances in the cluster are of the same size and have reached the maximum possible size, a notification will be sent to the engineer in charge (it will feature a higher priority level than successful scaling notifications);
- If the writer has the smallest size in the cluster, it receives the modification signal (instead of the reader) to switch to the next available instance type. Basically, the writer, at that point, migrates to the reader with the maximum size. This case is quite rare though, since that can only be achieved by a manual intervention under certain conditions.
Once the instance modification is complete, the RDS event subscription (RDS-EVENT-0014) is triggered, which will start the SNS. In turn, SNS triggers the second lambda function.
Note: That’s where AWS Step Function could come into play (if you opt to use it). The workflow it creates might be invoked instead of our RDS event subscription.
2. The Event function
Here’s how the second lambda function — Event — works:
- It gets the SNS via RDS Event Subscription;
- Then it performs all the same checks as the Alarm function;
- If it finds a
modifyingtag where no actual changes taking place, it removes the tag; - Next, it compares all instances against each other and triggers a modification for one of the smallest readers (randomly selected). Next, it attributes the
modifyingandmodificationTimestamptags; - If writer is the smallest instance — the size will be increased based on that;
- The resizing logic is the same as that of the Alarm lambda function, except that the Event function terminates when all instances in the cluster have become equal in size.
In a sense, the Alarm function stays idle until the Event function terminates: it always contains a modifying tag and will only be removed once all instances are equal in size.
Then, if the CloudWatch Alarm gets triggered once again and the cooldown period is over, the two functions will run in sequence. This will continue until the maximum available instance size in the cluster is reached.
The results
The flowchart below summarizes the vertical scaling algorithm for AWS databases that we implemented:
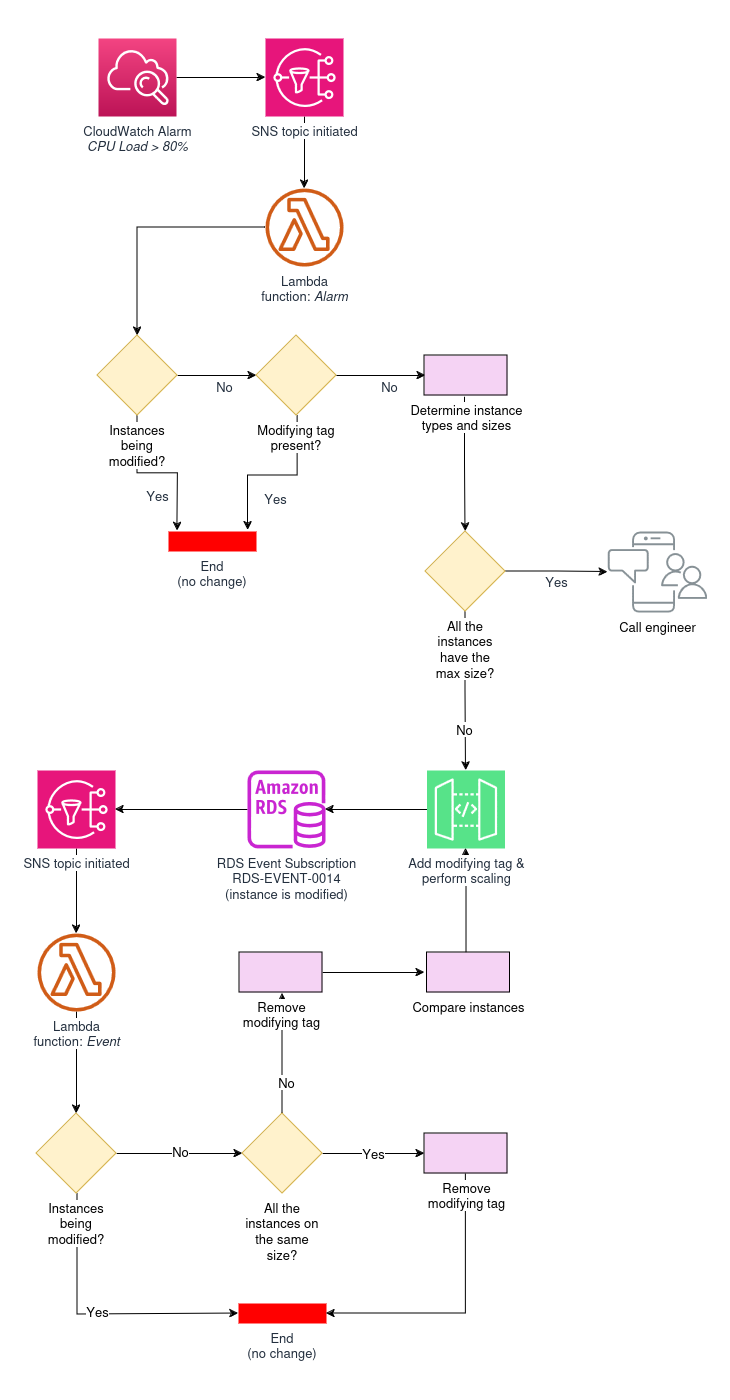
It proved to cut the mustard: the Aurora databases are now vertically scaled when needed. You’re welcome to try it for your needs! The abovementioned Lambda functions are written in Python, and you can find their source code in our GitHub repository.
Let’s finish up with the drawbacks of our approach. First of all, what about the downtime during this autoscaling? Normally, as the AWS documentation recommends, all RDS instances in the cluster are the same size. In this case, our algorithm affects the writer instance only once:
- First, we scale one of the readers.
- When one of the readers is scaled, we initiate a failover using it.
- Now, our writer (which became a reader) can be scaled, and then database operations can return to normal.
During our tests, this failover switch lasted about 10 seconds. However, its duration will depend on the size of your database and other factors. You can also leverage Amazon RDS Proxy to minimize your downtime. Our tests demonstrated a downtime reduction of up to 1-3 seconds for our case.
Additionally, there is no downscaling mechanism available at the moment. Following the modern FinOps trend, it would be reasonable to free up the resources for RDS when they are not in use for extended periods of time. In our case, downscaling was not originally envisioned for the project. However, we are considering adding such an improvement later.
Conclusion
This project demonstrated once again the wide range of customization and extensibility features AWS tools provide to address infrastructure challenges. We hope it will serve as inspiration for other users with similar goals. Had a similar experience? Feel free to share your thoughts in the comments below!

Thanks for interesting post!
Do you mean in your implementation? Technically it’s possible to downscale RDS.
Hi Vitaly! Right, it’s possible, but just not (currently) implemented in our functions/triggers.