

Our efforts in analyzing existing Kubernetes operators for PostgreSQL resulted in this comparison. And now we’d like to share our practical experience and fascinating lessons learned while using the solution of our choice — Postgres Operator by Zalando.
Installing & getting started
To deploy the operator, download the current release from GitHub and apply YAML files from the manifests directory. Alternatively, you can use the OperatorHub.
After the installation is complete, proceed to setting up log and backup storage. It is performed via the postgres-operator ConfigMap in the namespace where the operator is installed. Well, let us proceed to deploying the first PostgreSQL cluster.
Here is our deployment manifest:
apiVersion: acid.zalan.do/v1
kind: postgresql
metadata:
name: staging-db
spec:
numberOfInstances: 3
patroni:
synchronous_mode: true
postgresql:
version: "12"
resources:
limits:
cpu: 100m
memory: 1Gi
requests:
cpu: 100m
memory: 1Gi
sidecars:
- env:
- name: DATA_SOURCE_URI
value: 127.0.0.1:5432
- name: DATA_SOURCE_PASS
valueFrom:
secretKeyRef:
key: password
name: postgres.staging-db.credentials
- name: DATA_SOURCE_USER
value: postgres
image: wrouesnel/postgres_exporter
name: prometheus-exporter
resources:
limits:
cpu: 500m
memory: 100Mi
requests:
cpu: 100m
memory: 100Mi
teamId: staging
volume:
size: 2Gi
This manifest creates a cluster consisting of three instances with attached postgres_exporter sidecar containers used for exporting PostgreSQL server metrics. As you can see, the process is very straightforward, and you can deploy as many clusters as you like.
Of particular note is the graphical interface “for a convenient database-as-a-service user experience” called postgres-operator-ui. It is bundled with the operator and allows you to create and delete clusters as well as manage and restore operator backups.
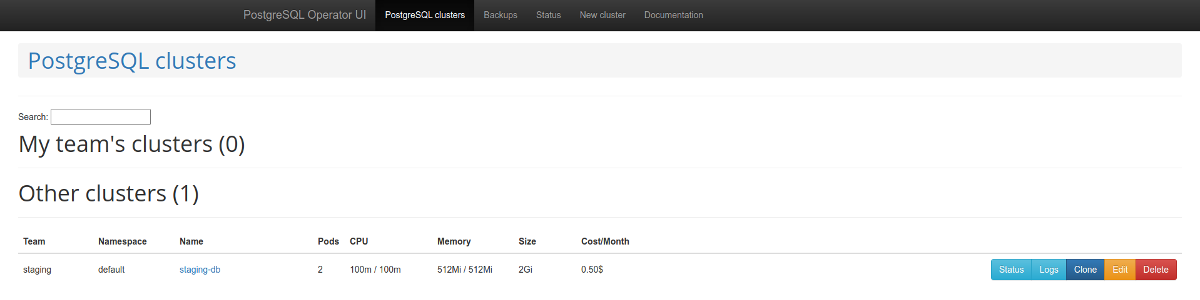
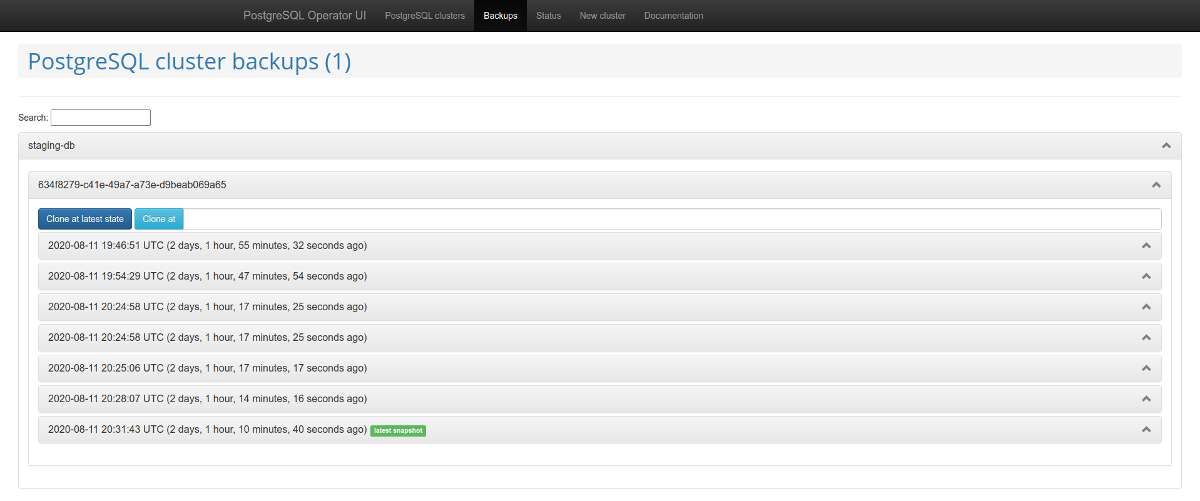
Another impressive feature of the operator is the support for the Teams API. Teams API automatically creates PostgreSQL roles using the list of user names. And then it can return the list of users for whom roles were automatically created.
Problems and solutions
However, we noted several pressing shortcomings with the operator:
- inability to disable backups;
- an issue with synchronous PostgreSQL clusters;
- privileges are not set by default when creating databases;
- sometimes, the documentation is not available or is outdated.
Fortunately, many of them can be solved. Let us start at the end (poor documentation) and work our way to the beginning of the list.
One day, you may find that there is no detailed description in the documentation on how to register a backup in the configuration and how to connect a backup bucket to the Operator UI. This PR can help you in solving this problem:
- you have to create a secret;
- and pass it to the
pod_environment_secret_nameparameter defined in the CRD of operator settings or in the ConfigMap (depending on the way the operator has been installed).
However, as it turned out, this is not possible. That is why we built our own version of the operator with some third-party additions; below, you will find more information regarding it.
If you pass backup parameters to the operator (namely, wal_s3_bucket and keys for accessing AWS S3), it will be making backups of the production as well as the staging database. We did not like such behavior at all.
However, we found an interesting loophole in the description of Spilo parameters (Spilo is a basic Docker wrapper for PgSQL): it turns out, you can pass an empty WAL_S3_BUCKET parameter, thus disabling backups. Happily, we stumbled upon a ready-made PR implementing such functionality, and we immediately merged it into our fork. Now you just need to add the enableWALArchiving: false parameter to the resource configuration of the PostgreSQL cluster.
As a matter of fact, there was another option: we could run two separate operators, one for the staging environment (with backups disabled) and another one for the production environment. But the way we chose helped us to handle everything with just one operator.
OK, we have devised a way to specify S3 parameters in database configs, and backups started getting into the storage. But how do you configure Operator UI to work with backups?

As it turns out, you need to add three following variables to the Operator UI:
SPILO_S3_BACKUP_BUCKETAWS_ACCESS_KEY_IDAWS_SECRET_ACCESS_KEY
After that, you will be able to manage backups. In our case, it simplifies operating the staging environment, allowing you to add production snapshots to it without any extra scripts.
Above, we mentioned the Teams API and its extensive options for creating databases and roles using the operator as a clear advantage. However, the roles created do not have appropriate privileges by default. In other words, a user with “read” access cannot read new tables.
Why is that so? The thing is, while the code has all the necessary GRANTs defined, they are not always applied. There are 2 methods: syncPreparedDatabases and syncDatabases. The syncPreparedDatabases does not apply privileges by default (although defaultRoles and defaultUsers keys are set in the preparedDatabases section of the manifest). Currently, we are preparing a patch to set these privileges automatically.
The mentioned issue with synchronous PgSQL clusters was reported here.
What have we got in the end?
While trying to solve all these problems, the Postgres Operator by Zalando was forked here, where we applied all the necessary patches to it. And we also have built a Docker image for convenience.
Here is a list of PRs merged into our fork:
- build a secure and lightweight operator image via Dockerfile;
- disable WAL archiving;
- update resource kinds to work with current K8s versions.
Please, support these PRs so they can make their way to the upstream in the next version of the operator (1.7).
Migrating production: our success story
Meanwhile, we’d like to share our migration experience. Yes, there is a way to migrate active and running production with minimal downtime using Zalando Postgres Operator and Patroni template.
With the Spilo Docker image, you can deploy standby-clusters using S3 storages and WAL-E. In this case, the PgSQL binary log is first saved to the S3 storage and then pulled by the replica. But what if you do not have WAL-E in the old infrastructure?
In this case, you can use PostgreSQL logical replication. However, we will not dive into the details of creating publications/subscriptions for this, because… well, our plan has failed.
The thing is our database had several highly-loaded tables containing millions of rows, and these rows have been constantly updated and deleted. The simple copy_data-based subscription (when a new replica copies all data from the master) could not keep up with the master. It copied the content for an entire week but never caught up with the master. In the end, we used the method proposed by our Avito colleagues: we transferred the data using pg_dump. So here goes our (slightly modified) version of their algorithm.
The idea is to create an “empty” subscription linked to an existing replication slot, and then fix the LSN number. In our case, there were two production replicas. This is important since the replica can help you to make a consistent dump and keep getting data from the master.
We will be using the following host designations while describing the migration process:
- master — the source server;
- replica1 — the streaming replica in the “old” production;
- replica2 — the new logical replica.
Migration plan
- Create a subscription to all tables in the
publicscheme of thedbnamedatabase on the master:psql -h master -d dbname -c "CREATE PUBLICATION dbname FOR ALL TABLES;" - Create a replication slot on the master:
psql -h master -c "select pg_create_logical_replication_slot('repl', 'pgoutput');" - Pause the replication on the old replica:
psql -h replica1 -c "select pg_wal_replay_pause();"Get LSN on the master:
psql -h master -c "select replay_lsn from pg_stat_replication where client_addr = 'replica1';" - Dump the data on the old replica (you can use several threads to speed up the process):
pg_dump -h replica1 --no-publications --no-subscriptions -O -C -F d -j 8 -f dump/ dbname - Upload the dump to the new server:
pg_restore -h replica2 -F d -j 8 -d dbname dump/ - After the uploading is complete, resume the replication on the streaming replica:
psql -h replica1 -c "select pg_wal_replay_resume();" - Create a subscription on the new logical replica:
psql -h replica2 -c "create subscription oldprod connection 'host=replica1 port=5432 user=postgres password=secret dbname=dbname' publication dbname with (enabled = false, create_slot = false, copy_data = false, slot_name='repl');" - Get an oid of the subscription:
psql -h replica2 -d dbname -c "select oid, * from pg_subscription;" - Say, our oid equals 1000. Apply LSN to the subscription:
psql -h replica2 -d dbname -c "select pg_replication_origin_advance('pg_1000', 'AA/AAAAAAAA');" - Enable the replication:
psql -h replica2 -d dbname -c "alter subscription oldprod enable;" - Check the status of the subscription; replication should be running:
psql -h replica2 -d dbname -c "select * from pg_replication_origin_status;" psql -h master -d dbname -c "select slot_name, restart_lsn, confirmed_flush_lsn from pg_replication_slots;" - If the replication runs normally and the databases are synchronized, you can switch to the new host.
- After the replication is disabled, you need to fix the sequences. (The detailed description of this process is available at wiki.postgresql.org.)
Thanks to this plan, the migration occurred with minimal delays.
Some other notes
Using Postgres Operator by Zalando on a daily basis, we’ve dealt with a variety of challenges. Here are some of our cases.
1. Private repositories
Once we needed to run an SFTP container in our PostgreSQL cluster via the operator to retrieve the database data in CSV format. The SFTP server with all the necessary parameters was stored in a private registry.
We were surprised to find out that the operator cannot deal with registry secrets. Fortunately, this problem was quite common, and we quickly solved it using the method devised by colleagues in this issue. It turned out we just needed to add a name and registry secrets to the ServiceAccount definition:
pod_service_account_definition: '{ "apiVersion": "v1", "kind": "ServiceAccount", "metadata": { "name": "zalando-postgres-operator" }, "imagePullSecrets": [ { "name": "my-fine-secret" } ] }'2. Additional storage and init containers
In the case of SFTP, we also needed to assign the correct directory permissions for the chroot to work. You might be aware of the fact that the OpenSSH server requires special directory access rights. For example, for a user to use its home directory (/home/user), the parent (/home directory) must be owned by root and needs 755 permissions. We decided to use an init container that would fix the permissions.
But then we discovered the operator could not mount the additional volumes in init containers! Fortunately, we found a related PR and added it to our build.
3. Recreating containers
Here goes our last (but not least) exciting problem. In the previous operator’s release, new global sidecars were added. Now you could define them in the operator’s CRD. Our developers noticed periodical restarts of the databases. The operator logs contained the following information:
time="2020-10-28T20:58:25Z" level=debug msg="spec diff between old and new statefulsets: \n
Template.Spec.Volumes[2].VolumeSource.ConfigMap.DefaultMode: &int32(420) != nil\n
Template.Spec.Volumes[3].VolumeSource.ConfigMap.DefaultMode: &int32(420) != nil\n
Template.Spec.Containers[0].TerminationMessagePath: \"/dev/termination-log\" != \"\"\nTemplate.Spec.Containers[0].TerminationMessagePolicy: \"File\" != \"\"\nTemplate.Spec.Containers[1].Ports[0].Protocol: \"TCP\" != \"\"\n
Template.Spec.Containers[1].TerminationMessagePath: \"/dev/termination-log\" != \"\"\nTemplate.Spec.Containers[1].TerminationMessagePolicy: \"File\" != \"\"\nTemplate.Spec.RestartPolicy: \"Always\" != \"\"\n
Template.Spec.DNSPolicy: \"ClusterFirst\" != \"\"\n
Template.Spec.DeprecatedServiceAccount: \"postgres-pod\" != \"\"\n
Template.Spec.SchedulerName: \"default-scheduler\" != \"\"\n
VolumeClaimTemplates[0].Status.Phase: \"Pending\" != \"\"\nRevisionHistoryLimit: &int32(10) != nil\n
" cluster-name=test/test-psql pkg=cluster worker=0As you know, there are several directives that are not defined but still added during the creation of a pod and container. These include:
- DNSPolicy;
- SchedulerName;
- RestartPolicy;
- TerminationMessagePolicy;
- …
It seems rational to assume that the operator takes this into account. But it turns out that it mistreats the ports section:
ports:
- name: sftp
containerPort: 22The TCP protocol is automatically added when creating a pod. However, the operator ignores this. To solve the above problem, you need to either delete the ports or add a protocol.
Conclusion
Kubernetes operators automate various tasks by using custom resources to manage applications and their components. However, this impressive automation brings in several unexpected nuances, so choose your operators wisely.
Our experience suggests that you should not expect to solve all the problems quickly and magically. Using Postgres Operator by Zalando, we’ve gone through some difficulties, but we are still pleased with the outcome and plan to extend our experience to other PostgreSQL installations.

@Nikolay Bogdanov. How do I configure additional users for pgbouncer ? How do I specify which users can access the connection pooler service ?