

Our clients tend to ask us: “Can we have a cheaper alternative to Amazon RDS?” or “Wouldn’t it be awesome to have something like RDS, not just in AWS…”. Well, to meet their needs and implement an RDS-like managed solution in Kubernetes, we took a look at the current state of the most popular PostgreSQL operators: Stolon, Crunchy Data, Zalando, KubeDB, StackGres. We compared them and made our own choice.
But before analyzing what we have in the world of K8s operators for PgSQL, let’s define general requirements for the potential replacement of Amazon RDS…
UPDATE (October’ 22): Please note there is a newer version of this article, where we examined another solution (CNPG) and provided an updated comparison of it with all operators mentioned here.
What is RDS?
In our experience, when people refer to “RDS”, they often mean a managed DBMS service that:
- is easy to set up;
- supports snapshots and can use them for recovering (preferably with PITR support);
- allows you to create a master/slave topology;
- has an extensive list of extensions;
- allows you to perform an audit and manage users/database access.
Generally speaking, the approaches to making RDS replacement can vary greatly, but the Ansible-like way does not suit us. In the Kubernetes ecosystem, operators are considered a generally accepted method of solving such tasks.
Bringing RDS to the Kubernetes landscape, we extend the essential features mentioned above with the following recommendations (requirements?..) for operators:
- ability to deploy them from Git and via Custom Resources;
- support for pod anti-affinity feature;
- ability to specify node affinity or node selector rules;
- support for pod tolerations;
- enough flexibility to be finely tuned;
- well-known technologies and even commands in use.
Without getting into details on these points (you’re welcome to ask your questions in the comments below), we would like to note that these parameters allow the user to define the specialization of cluster nodes more precisely for running specific applications on them. This way, we can strike the best balance between performance and costs.
There are several popular PostgreSQL operators for Kubernetes:
- Stolon;
- Crunchy Data PostgreSQL Operator;
- Zalando Postgres Operator;
- KubeDB;
- StackGres.
Let us take a closer look at them.
1. Stolon
![]()
Stolon by Sorint.lab boasts rich history: its first public release took place back in November 2015(!), and its GitHub repository has 3100+ stars and 40+ contributors.
This project is an excellent example of well-designed architecture:
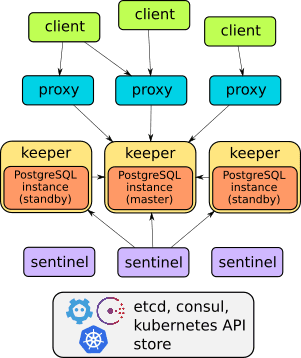
You can learn more about the operator in the project documentation. Overall, it has all the features mentioned above, such as failover functionality, proxies for transparent client access, backups. On top of that, proxies provide access through a single endpoint (unlike other solutions discussed below – they have two services for accessing the database).
Unfortunately, Stolon does not support Custom Resources, which complicates the creation of DBMS instances in the Kubernetes cluster. The stolonctl tool controls the Stolon cluster. The operator is deployed via a Helm chart, and user parameters are defined in the ConfigMap.
On the one hand, it turns out that Stolon is not an operator in its accurate sense (since it does not use CRDs). On the other hand, it is a flexible system allowing you to configure Kubernetes resources the way you feel comfortable.
In short, we felt the idea of generating a separate Helm chart for each DB is suboptimal. That is why we started looking for alternatives.
2. Crunchy Data PostgreSQL Operator
![]()
Operator by Crunchy Data seemed to be a good alternative. Its first version was released in March 2017. Currently, the Crunchy Data repository has 1500+ stars and 60+ contributors. The latest release (v4.6.0 from Jan’ 21) was tested to work with Kubernetes 1.17—1.20, OpenShift 3.11 & 4.4+, GKE, EKS, AKS, and VMware Enterprise PKS 1.3+.
The Crunchy Data PostgreSQL Operator architecture also meets our requirements:
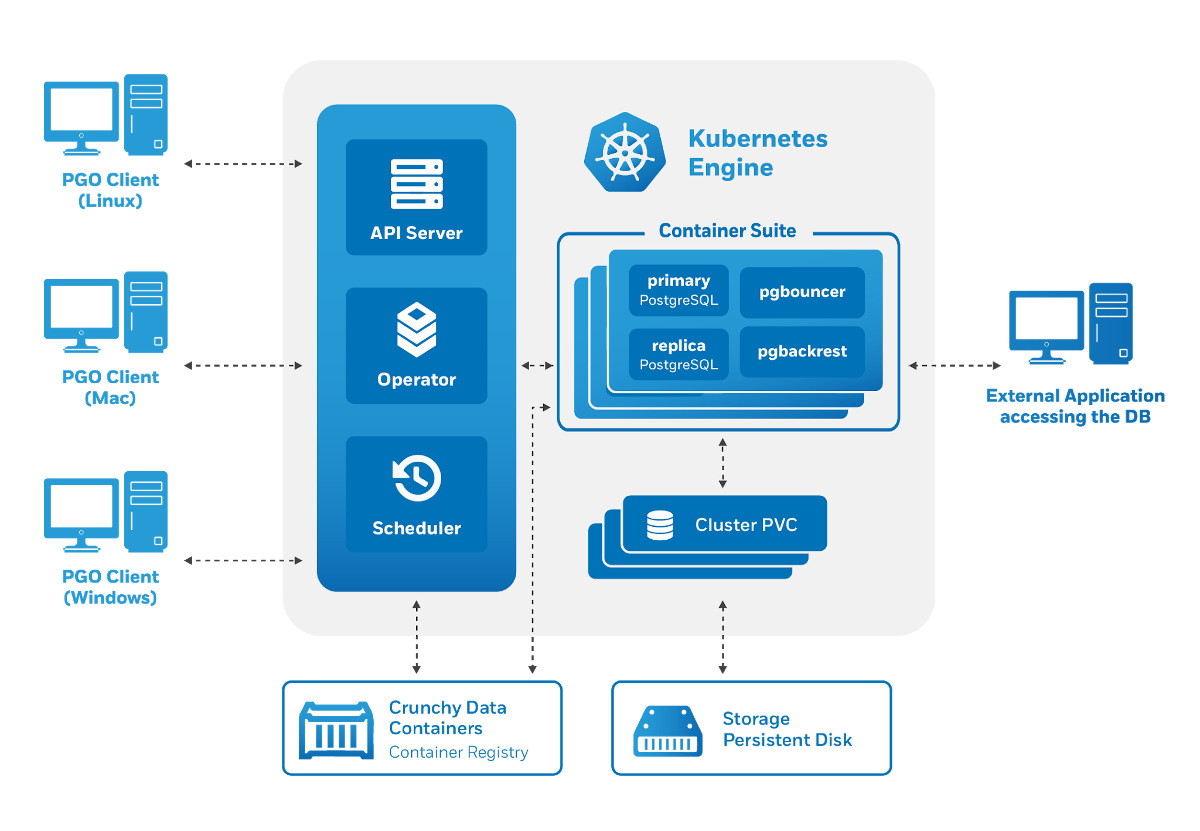
The tool called pgo manages the operator and generates Kubernetes Custom Resources. As potential users, we were pleased with the operator features, such as:
- support for CRDs;
- convenient user management (via CRDs);
- integration with other components of the Crunchy Data Container Suite – a specialized collection of PostgreSQL container images and useful tools (including pgBackRest, pgAudit, contrib extensions, and so on).
However, our attempts at using it exposed several problems:
- As it turned out, you cannot use tolerations in Crunchy Data, only
nodeSelectoris provided. (UPDATE: This feature is recently implemented, in v4.6.0 released in Jan ’21, however our evaluation has been made earlier, in 2020.) - The pods we created were a part of the Deployment (even though we have deployed a stateful application). As you know, unlike StatefulSets, Deployments cannot create volumes.
The second flaw has led to some funny results. For example, we were able to launch three replicas using the same local storage. Meanwhile, Crunchy Data stated that all three replicas are running normally (although that was far from reality).
Another notable feature of the operator is its built-in support for various auxiliary systems. For example, you can easily install pgAdmin and PgBouncer, and the documentation describes the installation of pre-configured pgMonitor, Grafana and Prometheus to collect & visualize metrics right out of the box.
Still, we felt the need to find another solution since the strange selection of the generated Kubernetes resources puzzled us.
3. Zalando Postgres Operator
![]()
We have a long history of using Zalando products: we have worked with Zalenium and tried Patroni, their popular PostgreSQL HA solution. Listening to Alexey Klyukin, one of the Postgres Operator authors, has made us like this project’s design and consider using it.
It’s younger than the first two solutions as its first release happened in Aug ’18 and it got a relatively small number of releases during its history. However, the project has come a long way and reached the popularity of Crunchy Data, as evidenced by 1500+ stars on GitHub and over 90 contributors.
Zalando Postgres Operator is based on proven solutions “under the hood”, such as:
Here is the architecture:
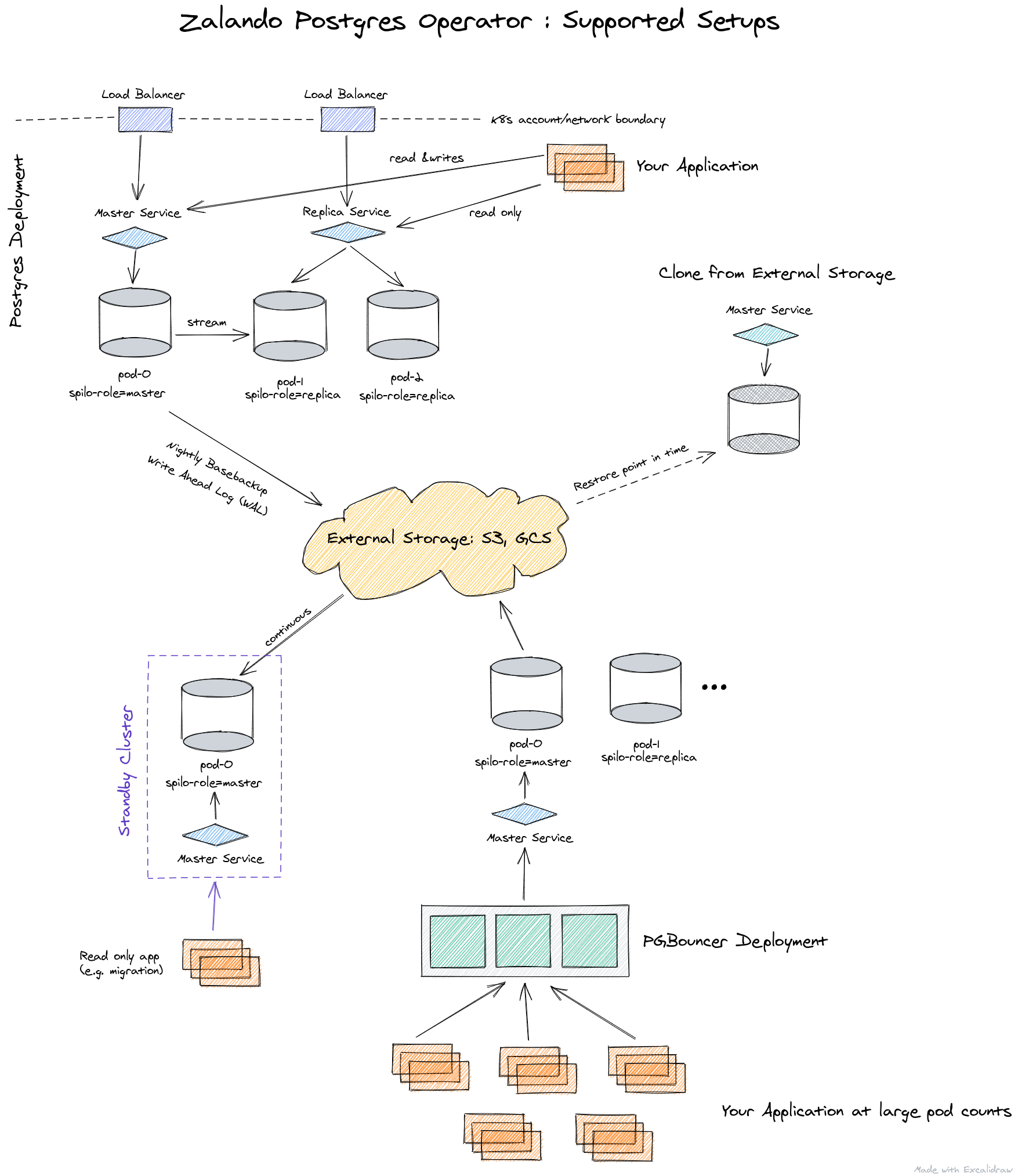
The operator is managed via Custom Resources. It can automatically create StatefulSets out of containers, and you can customize them later by attaching various sidecar containers to the pod. Thus, the Zalando operator compares quite favorably with the Crunchy Data operator.
In the end, we settled on the Zalando operator as our choice. We’ll fully describe its capabilities and show you how to use it in the next article. (UPDATE: This article is now available here!) And now it’s time for two more operators, StackGres & KubeDB, and the feature comparison table.
4. KubeDB
![]()
The AppsCode team has developed the KubeDB operator since 2017 and is well known in the Kubernetes community. Actually, KubeDB is positioned as a more “wide-scale” platform for running various stateful services in Kubernetes. It supports:
- PostgreSQL;
- Elasticsearch;
- MySQL;
- MongoDB;
- Redis;
- Memcache.
However, in this article, we will consider PostgreSQL only.
KubeDB implements an intriguing approach that involves several CRDs that contain various settings:
- The
postgresversions.catalog.kubedb.comresource stores the database image and additional tools; codesnapshots.kubedb.com— recovery parameters for backups;postgreses.kubedb.com — the central resource that uses all “underlying” resources and starts the PostgreSQL cluster.
KubeDB is not very customizable (unlike the Zalando operator), but you can manage PostgreSQL configuration via a ConfigMap object and use your custom image for Postgres.
Its exotic feature is the dormantdatabases.kubedb.com resource. It protects against unintended/wrong actions: all deleted databases are archived and copied to this resource, so you can restore them if/when necessary. The following diagram shows the lifecycle of the database in KubeDB:
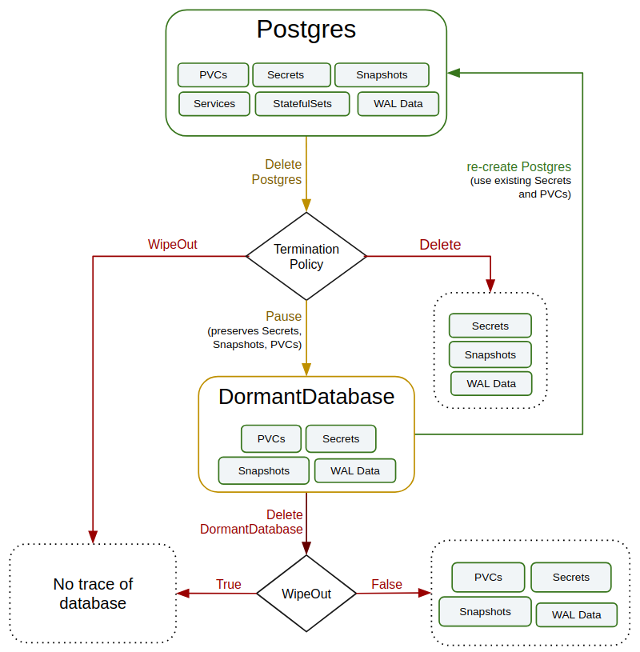
KubeDB uses in-house tools for managing clusters instead of the well-known Patroni or Repmgr. Meanwhile, PgBouncer is used for connection pooling. It is also created by a CRD (pgbouncers.kubedb.com). Here is a kubectl plugin as well: with it, you can manage databases using a familiar and well-known CLI tool, and this is a huge advantage against Stolon or Crunchy Data.
KubeDB integrates with other AppsCode solutions (similarly to Crunchy Data). If you rely heavily on this vendor’s tools, then KubeDB is an obvious and excellent choice.
Finally, I would like to draw your attention to the fact that this operator is very well documented, and all the documentation is stored in a separate GitHub repository. There are detailed usage examples, including thorough examples of CRD configuration.
However, KubeDB has disadvantages as well. Many features — including backups, connection pooling, snapshots, dormant databases — are only available in the enterprise version. To use them, you need to buy a subscription from AppsCode. Perhaps that’s why its GitHub repo is significantly less popular in the community, having less than 400 stars and 10 contributors.
Besides, the latest supported version of PostgreSQL out-of-the-box is 11.x. Whether these points negate the elegant architecture of KubeDB is up to you to decide.
5. StackGres
![]()
The StackGres operator is the youngest solution in our review, as it started quite recently, in May 2019. Since its main repo is hosted at GitLab, there is no way to compare the star number with GitHub. It makes use of well-known and proven technologies: Patroni, PgBouncer, WAL-G, and Envoy.
Here is how StackGres works in general:
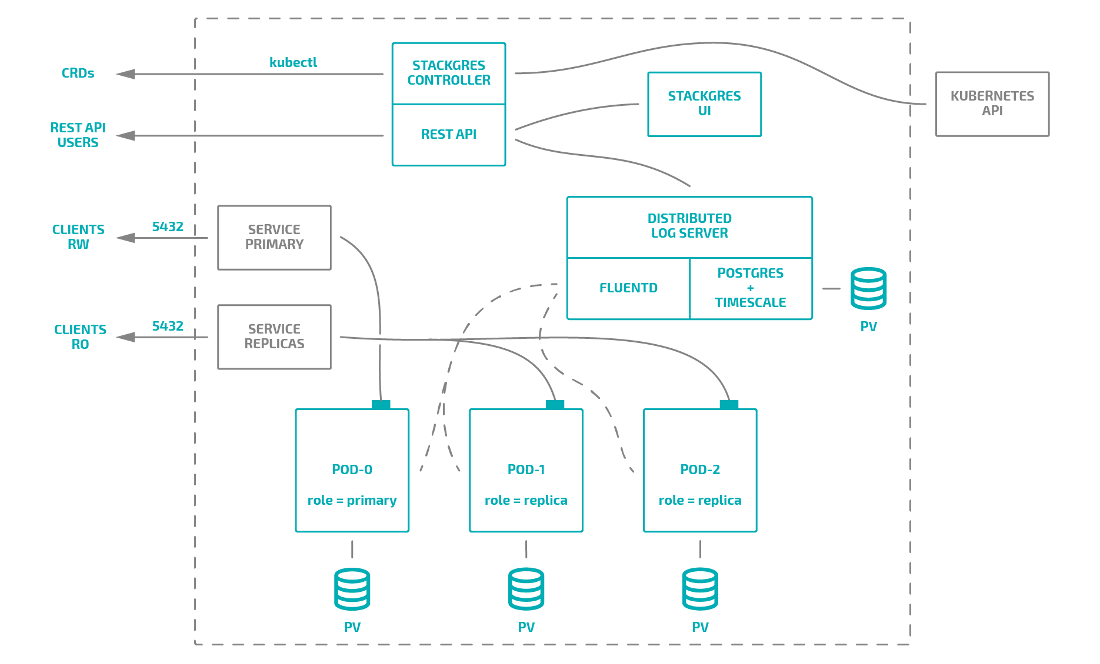
Also, together with the operator, you can install:
- a web panel (just like Zalando’s);
- a log collection system;
- a monitoring system similar to Crunchy Data’s;
- a MinIO-based backup aggregation system (you can also connect external storage).
This operator uses an approach similar to that of KubeDB’s: it provides several resources for defining cluster components, creating configuration files, and setting resources.
Here are CRD specifications:
sgbackupconfigs.stackgres.io,sgpgconfigs.stackgres.io,sgpoolconfigs.stackgres.ioallow you to define custom configs;sginstanceprofiles.stackgres.iospecifies the size of the Postgres instance (it will be used as a limit/request for the PostgreSQL/Patroni container). There are no limits for other containers;sgclusters.stackgres.io— if there are configurations for the database, connection pool, and backup, you can create a StackGres PostgreSQL cluster using these CRDs;sgbackups.stackgres.iois a resource similar to KubeDB’s snapshots, so it allows you to create and manage backups from within the K8s cluster.
However, the operator does not support custom image builds or multiple sidecar containers for the database server. The Postgres pod contains five containers:
Of these, we can disable the metrics exporter, the connection pooler, and the container with additional tools (psql, pg_dump, etc.). When starting the database cluster, StackGres allows you to use SQL scripts to initialize the database or create users. Regrettably, however, that is all you can do. This considerably limits customization abilities compared to, say, the Zalando operator. The latter allows you to attach sidecars containing Envoy, PgBouncer, or any other auxiliary containers (below, we will examine a good example of such a bundle).
To sum up, this operator would fit those who want to “merely manage” the PostgreSQL database in a Kubernetes cluster. StackGres is an excellent choice if you need a tool with clear and easy-to-understand documentation covering all aspects of the operator’s work and do not need to create complex configurations out of containers and databases.
The comparison
We know that our readers/colleagues enjoy summary tables, so we have composed one. It compares various Postgres operators for Kubernetes.
Hint: after considering two additional candidates, we still think that the Zalando operator is the optimal product for our use case. It lets us implement highly flexible solutions and has great potential for customization.
The first part of the table examines the essential features required to work with databases, the second one compares more specific functions (according to our beliefs about the ease of use of operators in Kubernetes).
UPDATE (October’ 22): Please note the second part of this article with an updated comparison table and another solution (CNPG) added.
It is also worth noting that we based our criteria for the summary table on examples from the KubeDB documentation.
| Stolon | Crunchy Data | Zalando | KubeDB | StackGres | |
| The latest version (at the time of writing) | 0.16.0 | 4.5.0 | 1.6.0 | v2021.01.26 | 0.9.4 |
| Supported PostgreSQL versions | 9.4—9.6, 10, 11, 12 | 9.5, 9.6, 10, 11, 12 | 9.6, 10, 11, 12, 13 | 9.6, 10, 11 | 11, 12 |
| General features | |||||
| PgSQL clusters | ✓ | ✓ | ✓ | ✓ | ✓ |
| Hot and warm standbys | ✓ | ✓ | ✓ | ✓ | ✓ |
| Synchronous replication | ✓ | ✓ | ✓ | ✓ | ✓ |
| Streaming replication | ✓ | ✓ | ✓ | ✓ | ✓ |
| Automatic failover | ✓ | ✓ | ✓ | ✓ | ✓ |
| Continuous archiving | ✓ | ✓ | ✓ | ✓ | ✓ |
| Initialization: using a WAL archive | ✓ | ✓ | ✓ | ✓ | ✓ |
| Instant and scheduled backups | ✗ | ✓ | ✓ | ✓ | ✓ |
| Managing backups in a Kubernetes-native way | ✗ | ✗ | ✗ | ✓ | ✓ |
| Initialization: using a snapshot + scripts | ✓ | ✓ | ✓ | ✓ | ✓ |
| Specific features | |||||
| Built-in Prometheus support | ✗ | ✓ | ✗ | ✓ | ✓ |
| Custom configuration | ✓ | ✓ | ✓ | ✓ | ✓ |
| Custom Docker image | ✓ | ✓ | ✓ | ✓ | ✗ |
| External CLI utilities | ✓ | ✓ | ✗ | ✓* | ✗ |
| CRD-based configuration | ✗ | ✓ | ✓ | ✓ | ✓ |
| Custom Pods | ✓ | ✗ | ✓ | ✓ | ✗ |
| NodeSelector & NodeAffinity | ✓ | ✓ | ✓ | ✓ | ✗** |
| Tolerations | ✓ | ✓ | ✓ | ✓ | ✗** |
| Pod anti-affinity | ✓ | ✓ | ✓ | ✓ | ✓ |
* KubeDB has a kubectl plugin.
** While node selectors are expected to work in the evaluated version of StackGres, we haven’t found this feature. The future v1.0 release of this operator should have both node affinity & tolerations support.
Conclusion
Managing PostgreSQL on Kubernetes is a non-trivial task. Perhaps, currently, there is no operator capable of covering all the needs of DevOps engineers. However, there are quite advanced and mature tools among the existing solutions, and you can choose one that best suits your needs.
Reviewing the most popular solutions, we opted for Postgres Operator by Zalando. Yes, there were some difficulties, and we will cover them in our next article. If you have experience with similar solutions, please, share it in the comments!

Funny thing is you skipped the only true fully open source Postgres operator from cloudnative-pg.io
These all have ties to vendors which is not becoming PostgreSQL.
Hi Jan! This article is almost 2 years old. We have the second part of it which is fully dedicated to CNPG and has an updated version of this comparison table: https://blog.palark.com/cloudnativepg-and-other-kubernetes-operators-for-postgresql/
I would also consider including License in Comparison,
Crunchy Data’s solution and KubeDB are not Open Source
Hi Peter! Thanks a lot for your great point! I thought Crunchy was fully Open Source, and it seemed to be true for their 4.x releases (which are reviewed in this old article).
We will investigate this a bit and add relevant information to the latest version of PgSQL operators comparison.
What is your opinion about Kubegress
https://www.kubegres.io/
Hi Jorge! Thank you for asking. AFAIK, we haven’t tried it yet. Would you recommend this option to operate PgSQL in Kubernetes?
I would love to see kubegres also.
Thanks for the reviews.
Excellent article, very well explained. Congratulations.