 SRE as a Service
SRE as a Service DevOps as a Service
DevOps as a Service Cloud & Kubernetes migration
Cloud & Kubernetes migration Infrastructure & CI/CD audit
Infrastructure & CI/CD audit R&D and technology consulting
R&D and technology consulting Kubernetes support
Kubernetes support Solution for SaaS
Solution for SaaS All services
All services

This article is a continuation of our series on PostgreSQL Kubernetes operators. The last part compared the Stolon, Crunchy Data, Zalando, KubeDB, and StackGres operators. We quickly looked at them and consolidated their features in a comparison table. In this piece, we’ll discuss CloudNativePG along with its features and capabilities and go on to update our comparison to include the new operator.
In late April 2022, EnterpriseDB released CloudNativePG, an Open Source PostgreSQL Apache 2.0-licensed operator for Kubernetes. The operator is flexible and easy to use, with a wide range of functions and detailed documentation.
Preparatory steps
To install CloudNativePG in Kubernetes, download the latest YAML manifest and apply it using kubectl apply. Once the installation is complete, the Cluster, Pooler, Backup, and ScheduledBackup CRD objects will become available (we’ll get to them later).
The operator works with all the supported PostgreSQL versions. In addition to the official PostgreSQL Docker images, you can use custom images that meet the conditions listed in the Container Image Requirements.
The spec.bootstrap section of the Cluster resource lists the available cluster deployment options:
- creating a new cluster (
initdb); - restoring it from a backup (
recovery). Note that point-in-time recovery (PITR) is also supported; - copying data from the existing PostgreSQL database (
pg_basebackup). This option can be helpful in migrating the existing database.
Here is a sample manifest defining a grafana-pg cluster of 3 instances with local data storage:
---
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: grafana-pg # Cluster name
spec:
instances: 3
primaryUpdateStrategy: unsupervised
storage:
storageClass: local
size: 1Gi
bootstrap:
initdb: # Deploying a new cluster
database: grafana
owner: grafana
secret:
name: grafana-pg-user
---
apiVersion: v1
kind: Secret # Secret with the database credentials
metadata:
name: grafana-pg-user
data:
username: {{ .Values.postgres.user | b64enc }}
password: {{ .Values.postgres.password | b64enc }}
type: kubernetes.io/basic-auth
The operator authors recommend creating a dedicated PostgreSQL cluster for each database. Thus, when creating a cluster via the initdb method, you can specify just one database in the manifest. This approach has many advantages; refer to Frequently Asked Questions (FAQ) to learn more about them.
You can manually create additional databases and users as a postgres superuser or run the queries specified in the spec.bootstrap.initdb.postInitSQL section after initializing the cluster.
Architecture, replication, and fault tolerance
This operator’s signature feature is avoiding external failover management tools, such as Patroni or Stolon (we reviewed it here). Instead, each Pod gets its own Instance Manager (available at /controller/manager) that directly interacts with the Kubernetes API.
If the liveness probe fails for some secondary PostgreSQL instance, the latter is marked broken, disconnected from -ro and -r services, and restarted. After restarting, the data is synchronized with the master, and the instance is activated, provided that all checks were successful. If there are any unexpected errors on the primary, the operator promotes the instance with minimal replication delay to the primary.
Curiously, the operator creates Pods with database instances instead of ReplicaSets or StatefulSets. For that reason, we recommend running multiple operator Pods to keep the cluster running smoothly. To do so, increase the number of replicas in the cnpg-controller-manager Deployment.
The operator supports asynchronous (default) and synchronous (quorum-based) streaming replication. minSyncReplicas and maxSyncReplicas control the number of synchronous replicas.
The way the operator uses local storage on the K8s nodes deserves special mention. It checks whether there is a PVC with PGDATA on the node for each new Pod and tries to use it by applying the missing WAL. If the attempt is unsuccessful, the operator begins to deploy a new PostgreSQL instance by copying data from the primary. In doing so, it reduces the network load as well as the time required to deploy new instances in the cluster.
To connect to PostgreSQL, the operator creates in the selected environment a dedicated (based on the cluster name) set of Services for each cluster for different access modes. For example, here is a list of Services for the grafana-pg cluster:
- grafana-pg-rw — read/write from the master instance;
- grafana-pg-ro — read from the replicas only;
- grafana-pg-r — read from any instance.
Note that grafana-pg-any is an auxiliary service and should not be used for connectivity.
Rich options for customizing the Kubernetes scheduler
The operator allows the user to set the desired affinity/anti-affinity rules and specify nodeSelector and tolerations for the Pods. The developers have enabled anti-affinity by default to distribute same-cluster PostgreSQL instances to different Kubernetes cluster nodes:
affinity:
enablePodAntiAffinity: true # Default value.
topologyKey: kubernetes.io/hostname # Default value.
podAntiAffinityType: preferred # Default value.The list of custom affinity/anti-affinity rules can be passed via additionalPodAntiAffinity and additionalPodAffinity, making the process even more flexible:
additionalPodAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: postgresql
operator: Exists
values: []
topologyKey: "kubernetes.io/hostname"Backing up and restoring data
CloudNativePG uses Barman – a powerful Open Source tool for PostgreSQL backup and recovery.
AWS S3, Microsoft Azure Blob Storage, and Google Cloud Storage — as well as S3-compatible services such as MinIO and Linode — can be used to store data. CloudNativePG supports several data compression algorithms (gzip, bzip2, snappy) and encryption.
The spec.backup section of the Cluster resource contains the parameters needed to configure backups. Here is a sample configuration for backing up data to S3-compatible storage:
backup:
retentionPolicy: "30d" # Archive retention period
barmanObjectStore:
destinationPath: "s3://grafana-backup/backups" # Path to the directory
endpointURL: "https://s3.storage.foo.bar" # Endpoint of the S3 service
s3Credentials: # Credentials to access the bucket
accessKeyId:
name: s3-creds
key: accessKeyId
secretAccessKey:
name: s3-creds
key: secretAccessKey
wal:
compression: gzip # WAL compression is enabledCloudNativePG will save WAL files to the storage every 5 minutes once it is connected. The Backup resource allows you to perform a full backup manually. As the name suggests, the ScheduledBackup resource is for scheduled backups:
---
apiVersion: postgresql.cnpg.io/v1
kind: ScheduledBackup
metadata:
name: grafana-pg-backup
spec:
immediate: true # Backup starts immediately after ScheduledBackup has been created
schedule: "0 0 0 * * *"
cluster:
name: grafana-pgNote that the spec.schedule notation differs from the cron one; it has 6 fields and includes seconds.
We recommend setting up scheduled backups, so you always have up-to-date backups in your storage. This comes with several advantages: the WAL applies faster to a recent backup. This prevents a situation in which a single manual backup will be erased from the storage once the retentionPolicy deadline has been reached, rendering it impossible to restore the data.
There are some noteworthy problems we encountered when configuring backups.
After enabling backups, we did several full backups for testing purposes. The files that we expected to end up in the storage were there, but the operator kept indicating that the backup was running:
kubectl -n grafana get backups.postgresql.cnpg.io grafana-pg-backup-1655737200 -o yaml
---
apiVersion: postgresql.cnpg.io/v1
kind: Backup
[...]
status:
phase: runningWe looked into it and discovered that status.phase was incorrect because Barman could not get the list of objects in the S3 bucket. It turned out that the endpointURL and destinationPath values were incorrect. These parameters set the endpoint URL of the S3 service as well as the directory path and can be specified using the Virtual-hosted-style or Path-style syntax. We could not find any information in the operator’s documentation regarding which syntax to use, so we used the first one:
backup:
barmanObjectStore:
destinationPath: "s3://backups/"
endpointURL: "https://grafana-backup.s3.storage.foo.bar"We converted the endpointURL to Path-style and rewrote the destinationPath to s3://BUCKET_NAME/path/to/folder. After that, the storage was able to connect, and the correct status.phase was displayed:
backup:
barmanObjectStore:
destinationPath: "s3://grafana-backup/backups" # Path to the directory
endpointURL: "https://s3.storage.foo.bar" # S3 service endpoint’s URL
kubectl -n grafana get backups.postgresql.cnpg.io grafana-pg-backup-1655737200 -o yaml
---
apiVersion: postgresql.cnpg.io/v1
kind: Backup
[...]
status:
phase: completed
Restoring data
You must have at least one full backup in the storage to be able to restore the data. Note that you cannot restore the data to the current cluster: you must define a new Cluster resource with a different name in the metadata.name section.
When restoring to an environment with the original PostgreSQL cluster, you can set the existing Backup resource in spec.bootstrap.recovery as the data source:
kubectl -n grafana get backups.postgresql.cnpg.io # Select a backup from the list
NAME AGE CLUSTER PHASE ERROR
[...]
grafana-pg-backup-1657497600 5h28m grafana-pg completed
---
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: grafana-pg-restore
spec:
[...]
bootstrap:
recovery:
backup:
name: grafana-pg-backup-1657497600
Use the storage to restore the data to other environments or Kubernetes clusters:
---
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: grafana-pg-restore # Name of the new cluster
spec:
[...]
bootstrap:
recovery: # The cluster will be populated from a backup
source: grafana-pg
recoveryTarget:
targetTime: "2022-07-01 15:22:00.00000+00" # Timestamp
externalClusters: # Define the cluster with the data to be restored
- name: grafana-pg # Source cluster name
barmanObjectStore: # Connection details for the storage
destinationPath: "s3://grafana-backup/backups"
endpointURL: "https://s3.storage.foo.bar"
s3Credentials:
accessKeyId:
name: s3-creds
key: accessKeyId
secretAccessKey:
name: s3-creds
key: secretAccessKeyNote that the name in spec.externalClusters must match the name of the original cluster. The operator uses it to search for backups in the storage. Caution: multiple clusters cannot be backed up to the same directory. Doing so would render the data irrecoverable.
In the example above, we performed PITR recovery, and the timestamp was defined by the bootstrap.recovery.recoveryTarget.targetTime parameter. If the bootstrap.recovery.recoveryTarget section is missing, the data will be restored to the last available WAL archive.
Status monitoring and alerts
The operator provides a kubectl plugin for cluster management in Kubernetes. You can use it to view the current cluster status, manage instance roles and certificates, reload and restart a certain cluster, enable maintenance mode, and export reports. Here is an example output showing the current cluster state:
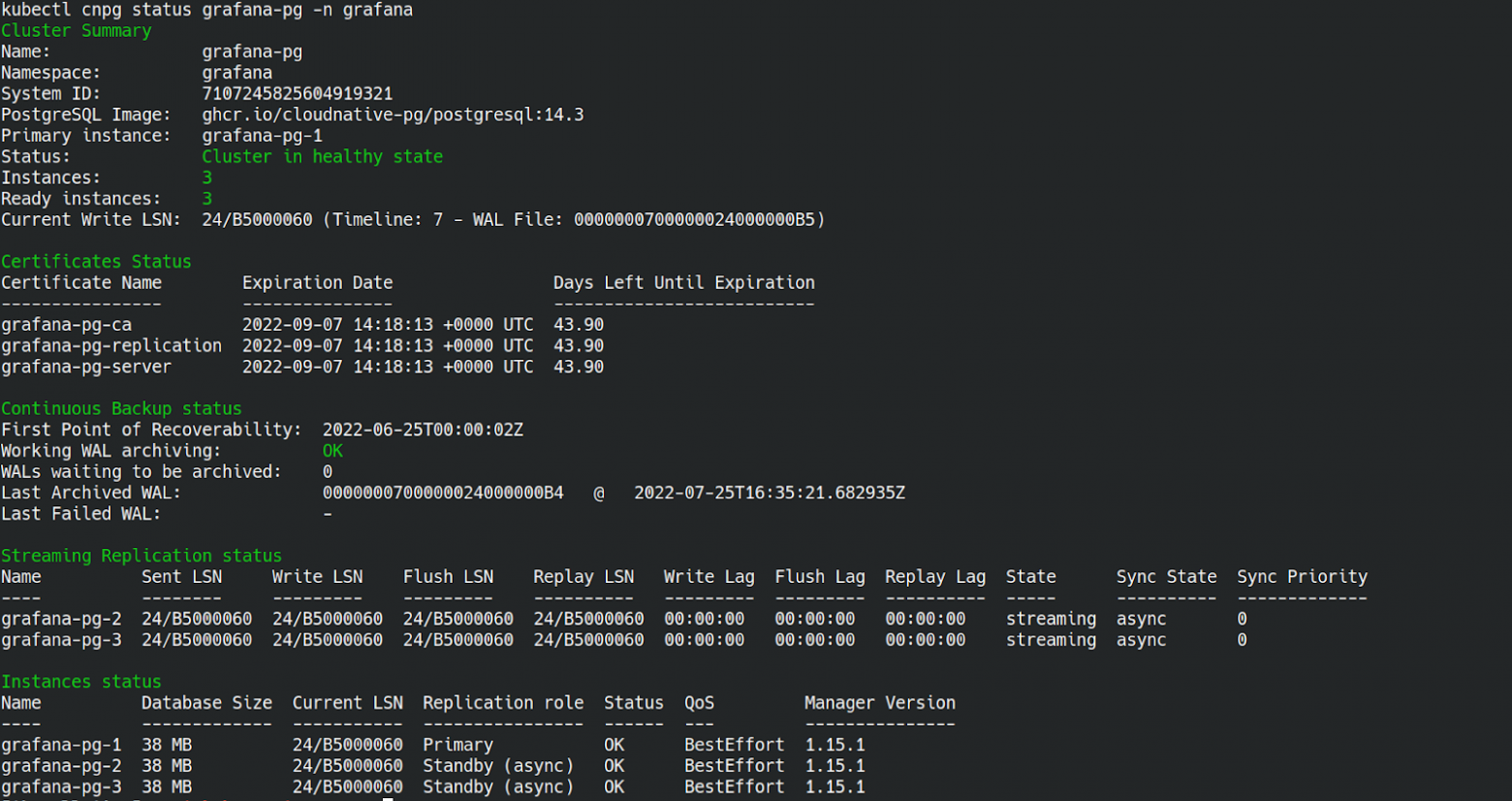
The kubectl cnpg status output includes information on replication status, instances, roles, certificates, and backups. Add --verbose or just -v to gain a more detailed version with information on the PostgreSQL configuration.
Each cluster instance has a separate metrics exporter endpoint, accessible at /metrics:9187. There is also a Grafana dashboard available:
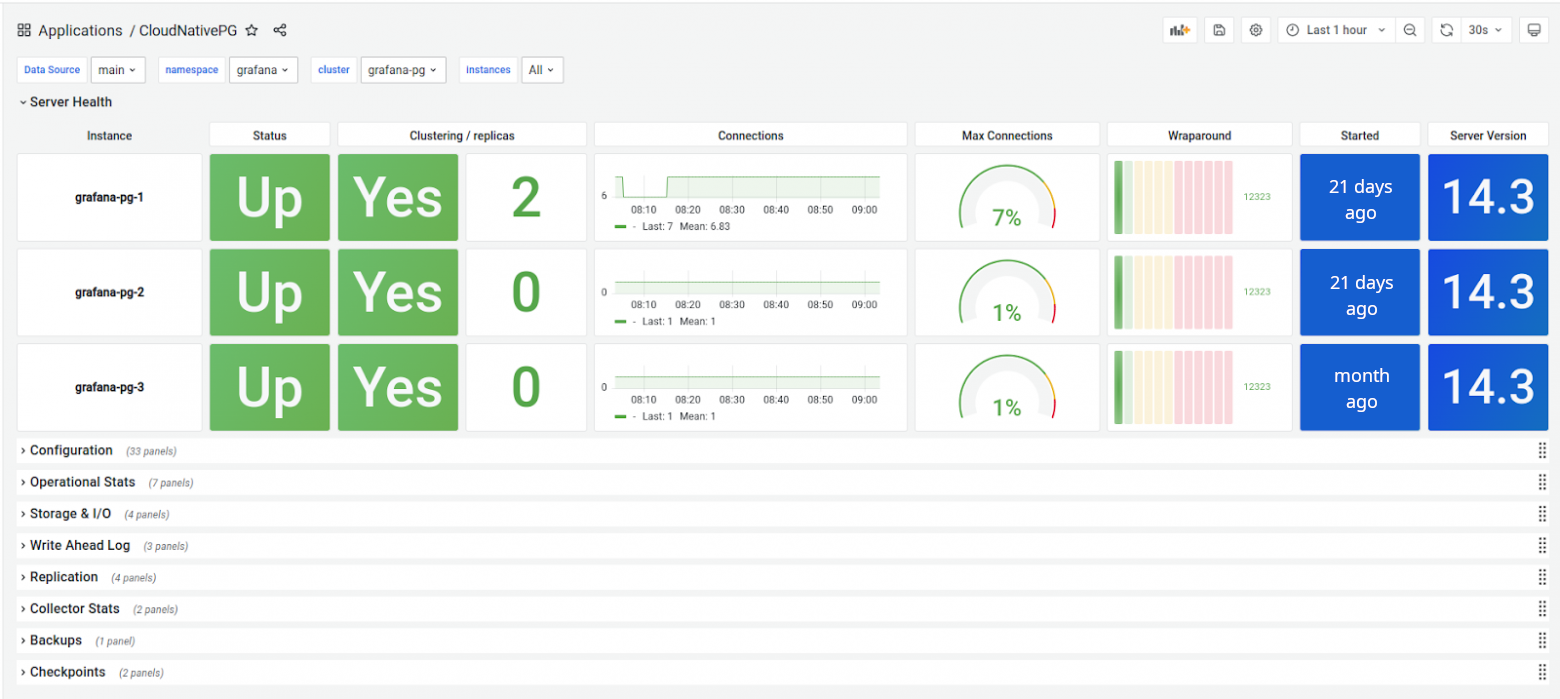
You can use metrics to configure Alertmanager alerts (see the examples in the GitHub repository).
Comparison table of all PostgreSQL operators
Here is our updated feature comparison table for different Kubernetes Postgres operators based on the previous article in this series:
| Stolon | Crunchy Data | Zalando | KubeDB | StackGres | CloudNativePG | |
| The latest version (at the time of writing) | 0.17.0 | 5.1.2 | 1.8.0 | 0.17 | 1.2.0 | 1.16.0 |
| Supported PostgreSQL versions | 9.6—14 | 10—14 | 9.6—14 | 9.6—14 | 12, 13 | 10-14 |
| General features | ||||||
| PgSQL clusters | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Hot and warm standbys | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Synchronous replication | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Streaming replication | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Automatic failover | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Continuous archiving | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Initialization: using a WAL archive | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Instant and scheduled backups | ✗ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Managing backups in a Kubernetes-native way | ✗ | ✗ | ✗ | ✓ | ✓ | ✓ |
| Initialization: using a snapshot + scripts | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Specific features | ||||||
| Built-in Prometheus support | ✗ | ✓ | ✗ | ✓ | ✓ | ✓ |
| Custom configuration | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Custom Docker image | ✓ | ✗ | ✓ | ✓ | ✗ | ✓ |
| External CLI utilities | ✓ | ✓ | ✗ | ✓* | ✗ | ✓* |
| CRD-based configuration | ✗ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Custom Pods | ✓ | ✗ | ✓ | ✓ | ✗ | ✓** |
| NodeSelector & NodeAffinity | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Tolerations | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Pod anti-affinity | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Other | ||||||
| License | Apache 2 | Apache 2*** | MIT | Source-available | AGPLv3 | Apache 2 |
* It has a kubectl plugin.
** Using PodTemplateSpec.
*** Crunchy Data PGO default installation method assumes installing container images distributed under the Crunchy Data Developer Program terms.
Takeaways
We really enjoyed using CloudNativePG. The features we have tried address most of the typical cluster administrator needs. You can quickly start a new PostgreSQL cluster and get fault tolerance right out of the box. We liked the variety of cluster deployment scenarios, flexible Kubernetes scheduler parameters, preconfigured metrics supplemented with exporters, as well as the ability to define custom metrics. The backup functionality is pretty capable but easy to configure and manage.
This article does not, however, claim to be an exhaustive guide to the operator’s capabilities. There is a lot of exciting stuff left out. For example, you can edit various operator parameters and fine-tune PostgreSQL. The operator also supports PgBouncer for connection pooling. You can enable and configure it via the Pooler custom resource. CloudNativePG can replicate the cluster, creating a new cluster on top of the old one, among many other things. The operator turned out to be feature-rich and well-thought-out. Our verdict is simple: Recommended!

The comparisons are helpful but incomplete without reviewing Kubegres.
Thanks, Thomas! We have plans to add Kubegres to our comparison as well.