

This article provides a summary of our experience deploying Keycloak, the popular single sign-on (SSO) solution, together with Infinispan, the in-memory data store for caching user metadata, to a Kubernetes cluster and ensuring stability and scalability in such a setup.
The scope of Keycloak
Keycloak (KC) is an Open Source software developed by Red Hat. It manages identity and access for applications running on application/web servers, such as WildFly, JBoss EAP, JBoss AS, etc. Keycloak allows you to add authentication to applications “with minimal hassle,” serving as an authorization backend practically without making any changes to the code. This guide provides a detailed description of that process.
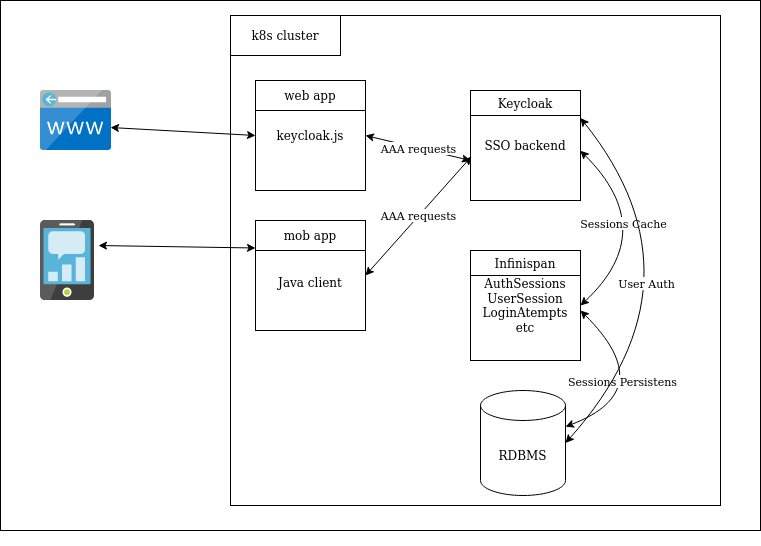
Typically, Keycloak is installed on a virtual or dedicated WildFly application server. Keycloak implements the SSO mechanism and authenticates users for all the integrated apps. Consequently, all users have to do is log in to Keycloak in order to use all the applications. The same is true for logout.
Keycloak supports some of the most popular relational database management systems (RDBMS): Oracle, MS SQL, MySQL, and PostgreSQL. In our case, Keycloak works with CockroachDB — a modern database released under the Business Source License, bringing about data consistency, scalability, and fault tolerance. One of its advantages is protocol-level compatibility with PostgreSQL.
Furthermore, Keycloak makes extensive use of caching: user sessions, authorization, and authentication tokens, as well as successful and unsuccessful authorization attempts, are all cached. By default, Keycloak uses Infinispan for storing all that data. Let’s take a closer look at it.
Infinispan
Infinispan (IS) is a scalable, highly available, in-memory key-value data store written in Java. It has been released under the Apache 2.0 Open Source license. Infinispan is primarily used for distributed caching but can also serve as a key-value store in NoSQL databases.
Infinispan can be run as a stand-alone server (cluster) or a built-in library extending functions of the core application.
The default Keycloak configuration makes use of the built-in Infinispan cache. The built-in library lets you set up distributed caching, enabling no-downtime data replication and migration. This way, even a complete reboot of the KC will not affect authorized users.
Since Infinispan is an in-memory data store, you can back up all the data to a database (CockroachDB in our case) to protect against memory overflow or an IS shutdown.
Objective
The customer used KC as the authorization backend for the application and wished to improve the solution’s resilience and ensure that the caches are safe regardless of whatever crashes/re-deployments may occur. So we were faced with two objectives:
- To ensure that the solution is fault-tolerant, reliable, and highly available.
- To preserve user data (sessions, tokens) in the event of a potential memory overflow.
Planning
Initially, the KC instance ran as a single replica with default caching settings (the integrated Infinispan with the in-memory storage). The data source was a CockroachDB cluster.
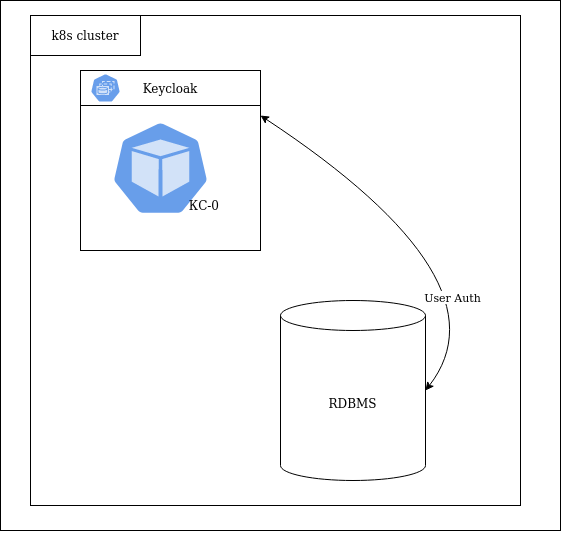
Several KC replicas had to be deployed to ensure availability. To this end, Keycloak provides several auto-discovery mechanisms. The initial step was to create 3 KC replicas using IS as a module/plugin:
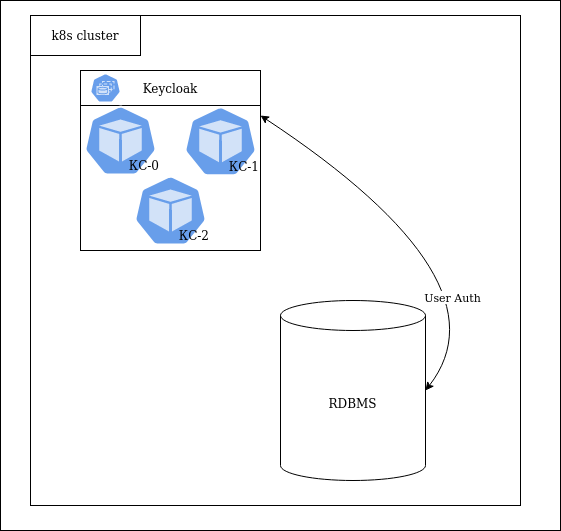
However, there are some features that IS running as a module lacks when it comes to customizing cache parameters: number of records, amount of memory used, and algorithms for pushing to permanent storage. Moreover, only the file system was allowed to be used as permanent data storage.
After that, our next step entailed deploying a standalone Infinispan cluster in Kubernetes and disabling the built-in IS module in the Keycloak settings:
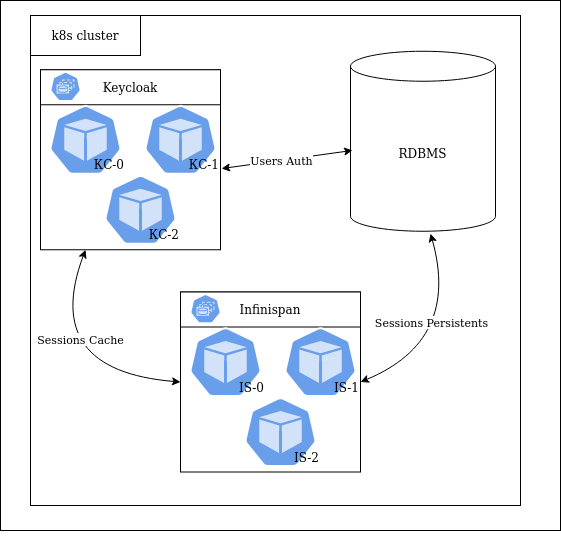
Three Keycloak/Infinispan replicas were running in a single namespace. This Helm chart served as the basis for our setup. At the same time, CockroachDB was running in a separate namespace. It was used together with the client application’s components.
Execution
You can find full examples of Helm templates mentioned below in this repository.
1. Keycloak
Keycloak supports several operating modes: standalone, standalone-ha, domain cluster, and DC replication. Standalone-ha mode is ideally suited for running in Kubernetes. With it, you can easily add/remove replicas while the shared configuration file is stored in ConfigMap. Moreover, a properly chosen deployment strategy ensures node availability during software upgrades.
While KC does not require persistent storage (PV/PVC), and the Deployment type can be used safely, we prefer StatefulSets. That way, you can set the node name (max length of 23 characters) in the jboss.node.name Java variable while configuring DNS_PING-based node discovery.
The following means are used to configure KC:
- environment variables that set the KC’s operating modes (standalone, standalone-ha, etc.);
- the
/opt/jboss/keycloak/standalone/configuration/standalone-ha.xmlfile for configuring Keycloak comprehensively and precisely; JAVA_OPTSvariables that define the behaviour of the Java application.
By default, KC uses the standalone.xml configuration file, which differs significantly from its HA counterpart. Let’s add the following lines to values.yaml to get the configuration we need:
# Additional environment variables for Keycloak
extraEnv: |
…
- name: JGROUPS_DISCOVERY_PROTOCOL
value: "dns.DNS_PING"
- name: JGROUPS_DISCOVERY_PROPERTIES
value: "dns_query={{ template "keycloak.fullname". }}-headless.{{ .Release.Namespace }}.svc.{{ .Values.clusterDomain }}"
- name: JGROUPS_DISCOVERY_QUERY
value: "{{ template "keycloak.fullname". }}-headless.{{ .Release.Namespace }}.svc.{{ .Values.clusterDomain }}"You can use the configuration file generated in the KC pod during the first run as the basis for .helm/templates/keycloak-cm.yaml:
$ kubectl -n keycloak cp keycloak-0:/opt/jboss/keycloak/standalone/configuration/standalone-ha.xml /tmp/standalone-ha.xmlThen, you can rename/delete the JGROUPS_DISCOVERY_PROTOCOL and JGROUPS_DISCOVERY_PROPERTIES variables to avoid re-generating this file every time KC is re-deployed.
Set the JAVA_OPTS parameters in .helm/values.yaml:
java:
_default: "-server -Xms64m -Xmx512m -XX:MetaspaceSize=96M -XX:MaxMetaspaceSize=256m -Djava.net.preferIPv4Stack=true -Djboss.modules.system.pkgs=org.jboss.byteman --add-exports=java.base/sun.nio.ch=ALL-UNNAMED --add-exports=jdk.unsupported/sun.misc=ALL-UNNAMED --add-exports=jdk.unsupported/sun.reflect=ALL-UNNAMED -Djava.awt.headless=true -Djboss.default.jgroups.stack=kubernetes -Djboss.node.name=${POD_NAME} -Djboss.tx.node.id=${POD_NAME} -Djboss.site.name=${POD_NAMESPACE} -Dkeycloak.profile.feature.admin_fine_grained_authz=enabled -Dkeycloak.profile.feature.token_exchange=enabled -Djboss.default.multicast.address=230.0.0.5 -Djboss.modcluster.multicast.address=224.0.1.106 -Djboss.as.management.blocking.timeout=3600"In order for DNS_PING to work correctly, set the following parameters:
-Djboss.node.name=${POD_NAME}, -Djboss.tx.node.id=${POD_NAME} -Djboss.site.name=${POD_NAMESPACE} и -Djboss.default.multicast.address=230.0.0.5 -Djboss.modcluster.multicast.address=224.0.1.106 Note that all the actions below are performed using the .helm/templates/keycloak-cm.yaml file.
Connecting the database:
<subsystem xmlns="urn:jboss:domain:datasources:6.0">
<datasources>
<datasource jndi-name="java:jboss/datasources/KeycloakDS" pool-name="KeycloakDS" enabled="true" use-java-context="true" use-ccm="true">
<connection-url>jdbc:postgresql://${env.DB_ADDR:postgres}/${env.DB_DATABASE:keycloak}${env.JDBC_PARAMS:}</connection-url>
<driver>postgresql</driver>
<pool>
<flush-strategy>IdleConnections</flush-strategy>
</pool>
<security>
<user-name>${env.DB_USER:keycloak}</user-name>
<password>${env.DB_PASSWORD:password}</password>
</security>
<validation>
<check-valid-connection-sql>SELECT 1</check-valid-connection-sql>
<background-validation>true</background-validation>
<background-validation-millis>60000</background-validation-millis>
</validation>
</datasource>
<drivers>
<driver name="postgresql" module="org.postgresql.jdbc">
<xa-datasource-class>org.postgresql.xa.PGXADataSource</xa-datasource-class>
</driver>
</drivers>
</datasources>
</subsystem>
<subsystem xmlns="urn:jboss:domain:ee:5.0">
…
<default-bindings context-service="java:jboss/ee/concurrency/context/default" datasource="java:jboss/datasources/KeycloakDS" managed-executor-service="java:jboss/ee/concurrency/executor/default" managed-scheduled-executor-service="java:jboss/ee/concurrency/scheduler/default" managed-thread-factory="java:jboss/ee/concurrency/factory/default"/>
</subsystem>Configuring caching:
<subsystem xmlns="urn:jboss:domain:infinispan:11.0">
<cache-container name="keycloak" module="org.keycloak.keycloak-model-infinispan">
<transport lock-timeout="60000"/>
<local-cache name="realms">
<heap-memory size="10000"/>
</local-cache>
<!-- Users, authorization, and keys are stored in the local cache - similarly to realms -->
<replicated-cache name="work"/>
<distributed-cache name="authenticationSessions" owners="${env.CACHE_OWNERS_AUTH_SESSIONS_COUNT:1}">
<remote-store cache="authenticationSessions" remote-servers="remote-cache" passivation="false" preload="false" purge="false" shared="true">
<property name="rawValues">true</property>
<property name="marshaller">org.keycloak.cluster.infinispan.KeycloakHotRodMarshallerFactory</property>
</remote-store>
</distributed-cache>
<!-- Sessions, offlineSessions, clientSessions, offlineClientSessions, loginFailures, and actionTokens in the standalone IS -->
<!-- Set owners = env.CACHE_OWNERS_AUTH_SESSIONS_COUNT (>=2) to preserve actionTokens during the re-deployment -->
</cache-container>
</subsystem>Configuring JGROUPS and DNS_PING:
<subsystem xmlns="urn:jboss:domain:jgroups:8.0">
<channels default="ee">
<channel name="ee" stack="tcp" cluster="ejb"/>
</channels>
<stacks>
<stack name="udp">
<transport type="UDP" socket-binding="jgroups-udp"/>
<protocol type="dns.DNS_PING">
<property name="dns_query">${env.JGROUPS_DISCOVERY_QUERY}</property>
</protocol>
...
</stack>
<stack name="tcp">
<transport type="TCP" socket-binding="jgroups-tcp"/>
<protocol type="dns.DNS_PING">
<property name="dns_query">${env.JGROUPS_DISCOVERY_QUERY}</property>
</protocol>
...
</stack>
</stacks>
</subsystem>
<socket-binding-group name="standard-sockets" default-interface="public" port-offset="${jboss.socket.binding.port-offset:0}">
<socket-binding name="ajp" port="${jboss.ajp.port:8009}"/>
<socket-binding name="http" port="${jboss.http.port:8080}"/>
<socket-binding name="https" port="${jboss.https.port:8443}"/>
<socket-binding name="jgroups-mping" interface="private" multicast-address="${jboss.default.multicast.address:230.0.0.4}" multicast-port="45700"/>
<socket-binding name="jgroups-tcp" interface="private" port="7600"/>
<socket-binding name="jgroups-tcp-fd" interface="private" port="57600"/>
<socket-binding name="jgroups-udp" interface="private" port="55200" multicast-address="${jboss.default.multicast.address:230.0.0.4}" multicast-port="45688"/>
<socket-binding name="jgroups-udp-fd" interface="private" port="54200"/>
<socket-binding name="management-http" interface="management" port="${jboss.management.http.port:9990}"/>
<socket-binding name="management-https" interface="management" port="${jboss.management.https.port:9993}"/>
<socket-binding name="modcluster" multicast-address="${jboss.modcluster.multicast.address:224.0.1.105}" multicast-port="23364"/>
<socket-binding name="txn-recovery-environment" port="4712"/>
<socket-binding name="txn-status-manager" port="4713"/>
</socket-binding-group>Finally, it is time to connect the external Infinispan:
<socket-binding-group name="standard-sockets" default-interface="public" port-offset="${jboss.socket.binding.port-offset:0}">
…
<outbound-socket-binding name="remote-cache">
<remote-destination host="${env.INFINISPAN_SERVER}" port="11222"/>
</outbound-socket-binding>
…
</socket-binding-group>Mount the resulting XML file to the container specified in the .helm/templates/keycloak-cm.yaml ConfigMap:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: keycloak-stand
spec:
serviceName: keycloak-stand-headless
template:
spec:
containers:
image: registry.host/keycloak
name: keycloak
volumeMounts:
- mountPath: /opt/jboss/keycloak/standalone/configuration/standalone-ha.xml
name: standalone
subPath: standalone.xml
volumes:
- configMap:
defaultMode: 438
name: keycloak-stand-standalone
name: standalone2. Infinispan
You can use the default configuration file (/opt/infinispan/server/conf/infinispan.xml) included in the infinispan/server:12.0 Docker image as the basis for .helm/templates/infinispan-cm.yaml.
First, you have to configure the auto-discovery mechanism. To do this, set the aforementioned environment variables in the .helm/templates/infinispan-sts.yaml file:
env:
{{- include "envs" . | indent 8 }}
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: JGROUPS_DISCOVERY_PROTOCOL
value: "dns.DNS_PING"
- name: JGROUPS_DISCOVERY_PROPERTIES
value: dns_query={{ ( printf "infinispan-headless.keycloak-%s.svc.cluster.local" .Values.global.env ) }}… and add the jgroups section to the XML config:
<jgroups>
<stack name="image-tcp" extends="tcp">
<TCP bind_addr="${env.POD_IP}" bind_port="${jgroups.bind.port,jgroups.tcp.port:7800}" enable_diagnostics="false"/>
<dns.DNS_PING dns_address="" dns_query="${env.INFINISPAN_SERVER}" dns_record_type="A" stack.combine="REPLACE" stack.position="MPING"/>
</stack>
<stack name="image-udp" extends="udp">
<UDP enable_diagnostics="false" port_range="0" />
<dns.DNS_PING dns_address="" dns_query="${env.INFINISPAN_SERVER}" dns_record_type="A" stack.combine="REPLACE" stack.position="PING"/>
<FD_SOCK client_bind_port="57600" start_port="57600"/>
</stack>
</jgroups>Note that we had to rebuild the Infinispan image and add a new version of the PostgreSQL SQL driver to it so Infinispan could properly interact with CockroachDB. We used the werf tool to re-build the image with the following werf.yaml file:
---
image: infinispan
from: infinispan/server:12.0
git:
- add: /jar/postgresql-42.2.19.jar
to: /opt/infinispan/server/lib/postgresql-42.2.19.jar
shell:
setup: |
chown -R 185:root /opt/infinispan/server/lib/Add the data-source section to the XML configuration file:
<data-sources>
<data-source name="ds" jndi-name="jdbc/datasource" statistics="true">
<connection-factory driver="org.postgresql.Driver" username="${env.DB_USER:keycloak}" password="${env.DB_PASSWORD:password}" url="jdbc:postgresql://${env.DB_ADDR:postgres}:${env.DB_PORT:26257}/${env.DB_DATABASE:keycloak}${env.JDBC_PARAMS_IS:}" new-connection-sql="SELECT 1" transaction-isolation="READ_COMMITTED">
<connection-property name="name">value</connection-property>
</connection-factory>
<connection-pool initial-size="1" max-size="10" min-size="3" background-validation="1000" idle-removal="1" blocking-timeout="1000" leak-detection="10000"/>
</data-source>
</data-sources>In Infinispan, you have to define the distributed-cache cache type in KC. Below is an example for offlineSessions:
<distributed-cache name="offlineSessions" owners="${env.CACHE_OWNERS_COUNT:1}" xmlns:jdbc="urn:infinispan:config:store:jdbc:12.0">
<persistence passivation="false">
<jdbc:string-keyed-jdbc-store fetch-state="false" shared="true" preload="false">
<jdbc:data-source jndi-url="jdbc/datasource"/>
<jdbc:string-keyed-table drop-on-exit="false" create-on-start="true" prefix="ispn">
<jdbc:id-column name="id" type="VARCHAR(255)"/>
<jdbc:data-column name="datum" type="BYTEA"/>
<jdbc:timestamp-column name="version" type="BIGINT"/>
<jdbc:segment-column name="S" type="INT"/>
</jdbc:string-keyed-table>
</jdbc:string-keyed-jdbc-store>
</persistence>
</distributed-cache>Repeat the process for other cache types as well.
The XML configuration file is mounted in a similar way to the Keycloak one.
That concludes our Keycloak and Infinispan setup.
Conclusion
Thanks to Kubernetes, you can easily scale the setup described above by adding Keycloak nodes to handle incoming requests or Infinispan nodes to increase cache capacity.
The project was completed over two months ago. We have not received any complaints from the customer; no problems have been detected since. Therefore, it is safe to say that the objectives were met: the resilient and scalable SSO solution is up and running.

Have you come across any issues with the multi-node infinspan cache not recovering after a database outage. A single node seems to recover number multiple nodes don’t
Hello,
Thank you for this interesting post.
We are trying to achieve the same goal but we encounter a big issue.
When we enable JDBC persistence, we can create a session and it appears in DB with a correct timestamp (something like 1646822071).
But each time we are using the token with another client, the timestamp in database is update to a wrong value (something like 35987999).
More details and a reproducer here : https://github.com/keycloak/keycloak/discussions/10577
Do you have an idea on what is going on here ? It seems unusable if the SSO on multiple client can not work…
Thanks a lot