

What if I tell you that there is a faster alternative to Redis? KeyDB is a relatively young and little-known project that lacks broad public coverage as of now. We have recently got the chance to use it, and now are eager to share our experience.
The backstory is rather trivial: one day, a massive influx of traffic led to significant degradation of a web application’s performance (namely, the response time). At that moment, we failed to diagnose the root of the problem, so we decided to conduct several load tests later. During the testing, we found the bottleneck in the system, which was the cache of the Redis database. As is often the case, for various reasons at that moment, we could not solve the problem the correct way (by asking developers to change the application logic). Being curious, we tried to find out an elegant and simple workaround. And that is how this article came into existence.
The root of the problem
A word about Redis
As you know, Redis is a single-threaded database. To be more precise, it is single-threaded when processing user data. Internal operations are multi-threaded, starting with version 4 of Redis. However, this change has affected only a small portion of the load since the majority of Redis operations are related to processing user data.
This topic has been a subject of intense debate for a long time. Still, Redis developers refuse to implement full-fledged concurrency by stating that it would greatly complicate the application and increase overhead while boosting the number of bugs. If you feel that a single thread is not enough, they state, then you have a problem with the application design, and you need to improve it. Another group of users believes that Redis developers create a bottleneck by refusing multi-threading. In the case of really high loads — sooner or later — this problem will inevitably manifest itself, which imposes significant restrictions on application design and/or unnecessarily increases its complexity.
Judging who is right is not the purpose of this article. Instead, I’d love to share our experience in one specific case as well as a solution to the problem encountered.
The case
The developers of one of our customers set up an extremely aggressive caching of PostgreSQL data through Redis. At that moment, this was the only way to protect PostgreSQL from sudden traffic influx and, as a result, to keep an application functioning.
After a bunch of load testing, we analyzed the situation and found that the single-threading of Redis was a limiting factor in our experiments. How does it happen? Redis consumes all available resources of its CPU core, and then rapid degradation of an application performance follows. The degradation is exponential: everything stalls as soon as Redis reaches its performance limit.
It looked more or less like this:
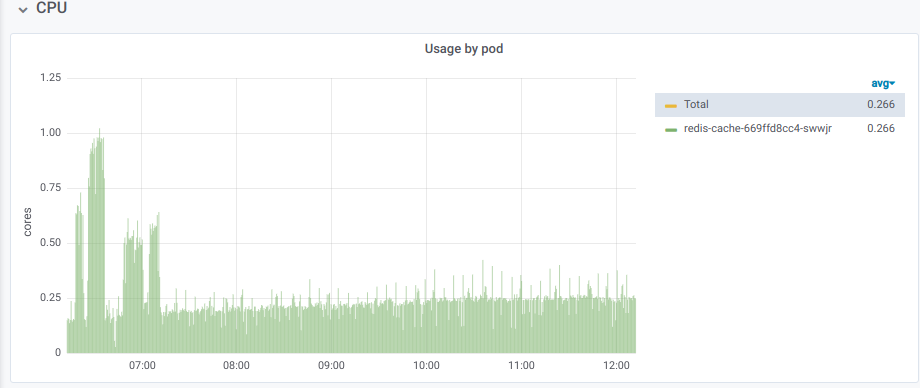
There was an obvious problem as evidenced by New Relic:
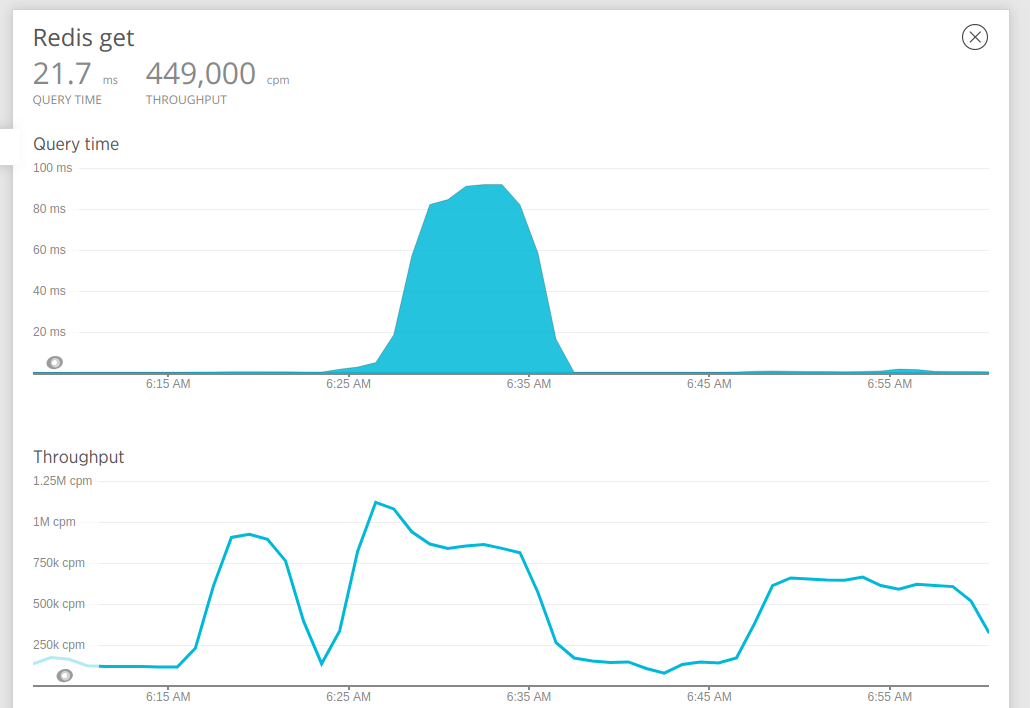
And here are the stats for the get operation in Redis:
We reported the problem to developers, and they replied that “it is impossible to solve it right away.” So, we began searching for a solution on the operating side and settled on KeyDB.
Before proceeding to review KeyDB, I would like to note that the project in focus uses a standalone Redis database since the Sentinel-based cluster solution has much higher latency. As one of the apparent solutions, you can create replicas of the cache and connect the application to it through a load balancer. However, after consulting with developers, we rejected such an idea due to the active and complicated mechanism of cache invalidation in the application. The same went for sharding the cache.
A quick introduction to KeyDB
While searching for a possible solution, we stumbled upon a database called KeyDB. KeyDB is a fork of Redis developed by a Canadian company and distributed under the BSD license. The project is rather young: it was launched at the beginning of 2019. One day, its originators encountered similar limitations of Redis. So they decided to make their own fork. It has successfully solved long-standing problems as well as got extended features, which are available only in the enterprise version of Redis.
If you would like to learn more about KeyDB, here is an excellent introductory article on Medium. It presents DBMS and provides basic benchmarking that compares KeyDB’s performance with its parent, Redis.
First of all, we treated KeyDB as a potential solution to our problems. We also liked its extended features and abilities, such as:
- full-fledged multi-threading;
- full and absolute compatibility with Redis (this factor was critically important for us since we could not modify the application itself), which also meant a hassle-free migration;
- built-in mechanism for backing up data to Amazon S3 storage;
- simple-to-set-up active replication;
- straightforward clustering and sharding without the need for Sentinel and other auxiliary software.
3000+ stars on GitHub and a large number of contributors also looked promising. The application is actively developed and maintained, which is confirmed by a large number of commits, intense discussions on issues as well as numerous closed/accepted PRs. The chief maintainer is always quick-to-react, friendly, and helpful. In other words, KeyDB fits our needs perfectly.
Migration and results
We knew that the migration would be a sort of gamble (because of the relative newness of KeyDB), but we still decided to make it happen. We were comforted by the fact that it was easy to roll back changes since the entire infrastructure is deployed in the Kubernetes cluster, and the built-in K8s’ Rolling Update mechanism is well-suited for such tasks.
We prepared Helm charts, switched the application in the testing environment to the new database, and performed a rolling update. Then we presented our results to the customer’s QA team.
The testing lasted for about a week, but the details of it were sketchy (for us). All we know is that the customer verified standard Redis functions via the phpredis PHP driver as well as performed QA testing of the UX. Then they gave us the green light since no side effects were detected. In other words, for the application, nothing has changed at all.
It is worth noting that the configuration file stayed (almost) the same: we only replaced the name of an image used. The same is true for monitoring and exporting metrics to Prometheus: the most common exporter works great with KeyDB and does not require any modifications. As you can see, from the point of operation, it was an ideal migration.
It allows you to keep everything as-is after switching the application to a new DBMS and leave the system under the load for some time just to be safe. However, if you would like to see a performance increase (or at least some changes), you have to keep in mind that by default, KeyDB works exactly like Redis, meaning that the server-threads parameter in KeyDB is set to 1.
After switching, testing, and running for some time with the new database (KeyDB), we repeated load testing with the same settings that were used for Redis. I bet you are anxious to see the results.
As you can see from the CPU load chart, we finally got rid of the single-core problem: now the process can use all available resources:
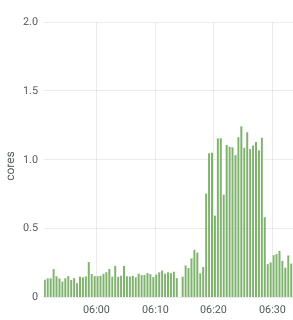
Well, our further attempts at load-testing forced the application to use up to three CPU cores.
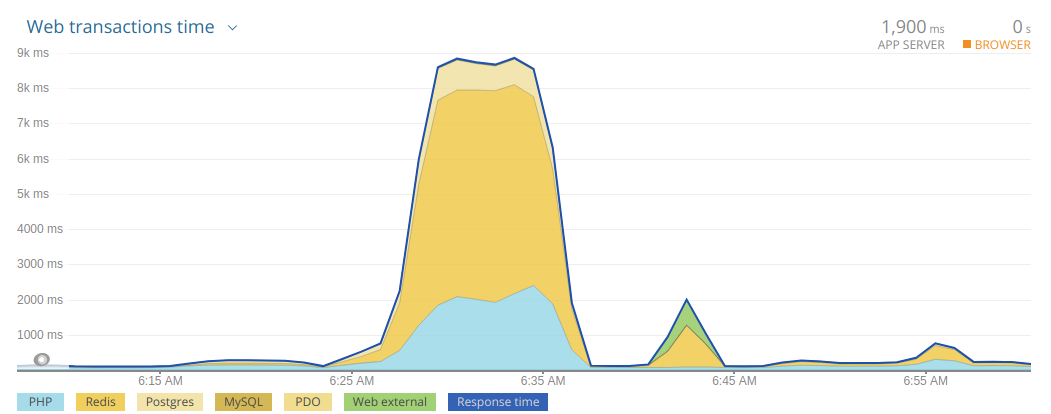
New Relic metrics showed that the application under the same load became much more adequate. There still was some performance degradation, but, as you can see, it was much less pronounced compared to the graph above:
![]()
The latency for the new database (KeyDB) was also somewhat higher while staying within acceptable limits:
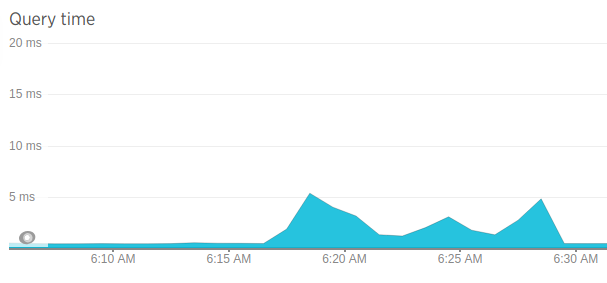
The next graph shows that the number of requests to KeyDB is the same:
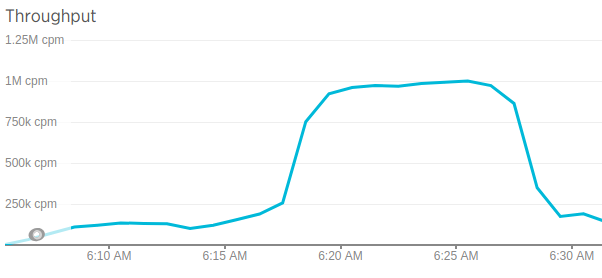
Summing up the results of these synthetic tests, we can say that both Redis and KeyDB exhibit significant performance degradation in latency (40+ ms) when there is a notable increase in parallel connections (1000+). In our case, web application increased the latency of Redis even with a lower number of connections (400+), while in KeyDB, the latency remained acceptable.
Conclusion
This example perfectly illustrates the power of the Open Source community when it comes to advancing promising projects. One day I came across an interesting idea, the point of which boils down to the following: some large company develops an impressive product, makes part of it free-to-use, but leaves the most valuable features closed and provides them on a paid basis. The Open Source community uses that product for a while, and then someone decides to fork it and make its own version, implement those features, and open them to everyone. Well, KeyDB is one of those cases.
Speaking of the migration itself (which was surprisingly hassle-free), the increase in productivity was not as high as you might expect by looking at the graphs provided by the creators of KeyDB. Well, this is only our particular case that has many nuances and deviations (including the notorious application design — e.g., a large number of get commands in Redis instead of a more efficient mget variation of aggregate requests). Nevertheless, we managed to achieve positive results and gain access to some useful functions (which we have not implemented yet, though).
Overall, KeyDB looks tempting. When we acquire enough real-life experience with this DBMS (which is yet to be done), we will consider its broader use in other projects and settings.
This article should not be seen as a guide or a call to abandon Redis in favour of KeyDB. Despite our positive experience, KeyDB is no silver bullet, obviously. Our case was the highly specific one: we needed to solve the short-term, local problem rapidly and at a minimum cost. KeyDB fitted our conditions perfectly. I don’t know if KeyDB will be right for you. At least, now you are aware that such a possibility exists.
* Redis is a registered trademark of Redis Ltd. Any rights therein are reserved to Redis Ltd. Any use by Palark GmbH is for referential purposes only and does not indicate any sponsorship, endorsement or affiliation between Redis and Palark GmbH.

Comments