 SRE as a Service
SRE as a Service DevOps as a Service
DevOps as a Service Cloud & Kubernetes migration
Cloud & Kubernetes migration Infrastructure & CI/CD audit
Infrastructure & CI/CD audit R&D and technology consulting
R&D and technology consulting Kubernetes support
Kubernetes support Solution for SaaS
Solution for SaaS All services
All services

Although many businesses can benefit from using Kubernetes, it’s notorious for its difficulty*. Its complexity and steep learning curve are often overwhelming to users, leading them away rather than towards adoption or outsourcing them to managed service providers. With our years of Kubernetes experience, we fully understand this frustration.
While preparing for DevOpsConf 2021, we came up with a simple metaphor of Kubernetes as an iceberg to visualize the problem of its complexity.
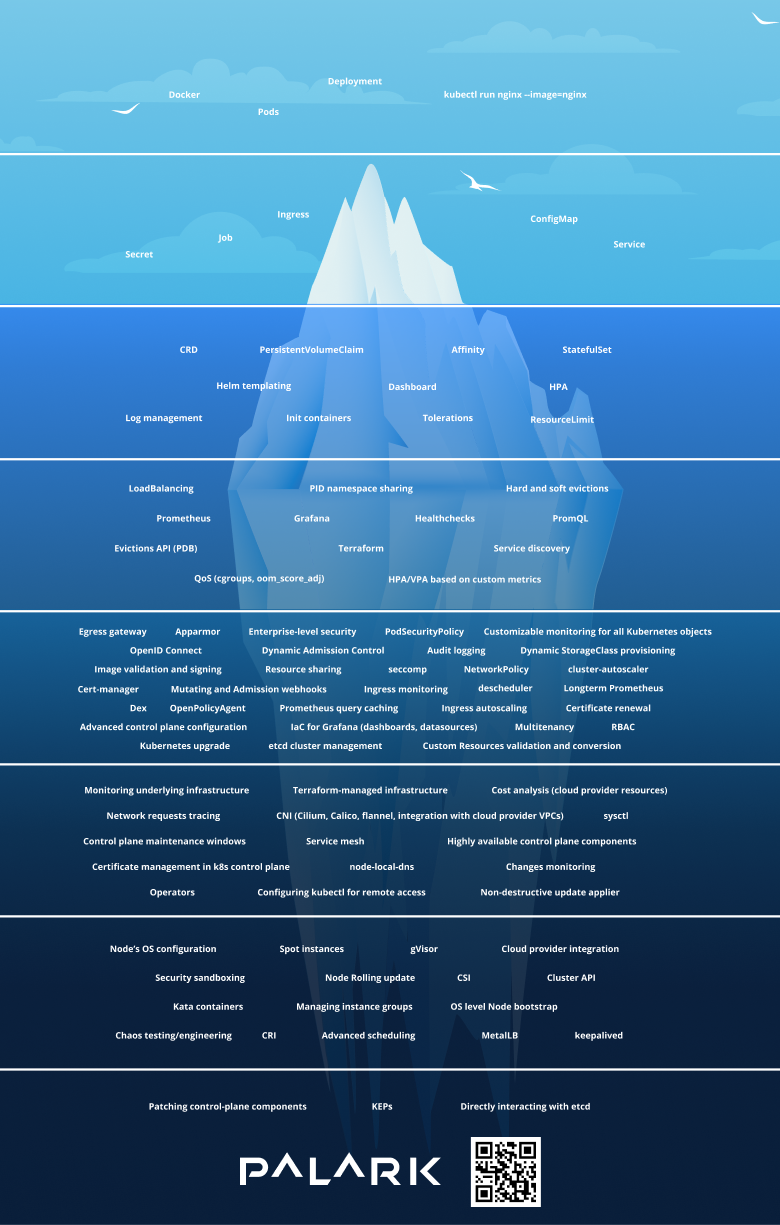
Kubernetes is an ever-evolving system that can seem a bit intimidating at first. When getting started, things like Docker, Pods, Deployment, and NGINX are easy enough to understand. Then you stumble upon Secrets, Jobs, Ingresses, ConfigMaps, and Services. Those are a bit more tricky, but still okay, aren’t they?
However, the deeper you dive, the harder it gets. How confident will you feel out there in the depths? What kind of expertise do you need, and what do you want to be able to do?
Our experience in providing Managed Kubernetes services and developing our own Kubernetes platform shows that the first two levels are sufficient for most (say, 85%) tasks. This level of proficiency in K8s and its primitives is essential for most developers today.
Of course, you can dive even deeper. Log collection, horizontal scaling, working with StatefulSets, Helm templating – this is the knowledge that every senior developer should have.
What’s next? Closer to the bottom, things get even more intriguing. Okay, a true Kubernetes geek should know how to deploy Kubernetes, connect to Service Discovery, and use PromQL to interact with the Prometheus monitoring service, among other things. Here, in our opinion, common sense suggests that there is no point in digging any deeper. Equipped with this knowledge, you will be able to solve 99% of your Kubernetes tasks.
Who is ready to dive into much darker depths? Who is willing to use their resources to create KEPs (Kubernetes Enhancement Proposals) to improve Kubernetes upstream? Direct modifying your Kubernetes’ etcd data? Well, we had such an experience in Palark. But does it make sense to employ an in-house team to handle such tasks? Probably not.
That is why many users prefer managed Kubernetes offerings (such as Google GKE or Amazon EKS) or ready-to-use platforms — such as OpenShift and Rancher — instead of managing K8s on their own. This is confirmed by the latest market trends.
But back to the iceberg…
Community reaction
After that conference, many people who liked the Kubernetes iceberg asked us to share it with the broader community.
Thus, we recently featured it on social networks… and the community response was just overwhelming! Hundreds of thousands(!) of views as well as tons of likes & reposts. This iceberg essentially became a meme in some way.
Chris Short of the Kubernetes team at AWS, who is also an active Kubernetes contributor and co-chair of OpenGitOps, called this iceberg a “great conceptual way to learn Kubernetes and associated cloud native bits.”
Another remarkable outcome of our post was Anton Sankov’s “Demystifying the Kubernetes Iceberg” series of articles. The author set himself the ambitious goal of explaining all the components of the iceberg, turning the meme into something really practical — educational. These articles also gained much attention from the engineering community, including being featured in the DevOps’ish, DevOps Bulletin, DevOps weekly newsletter, etc.
We are happy to see how our simple metaphor facilitates knowledge sharing. As more people dive deeper, the less “scary” the iceberg becomes. That is true even for those who don’t need to use the technology directly.
* Is Kubernetes actually hard?
Well, this popular belief is not just about the “Kubernetes The Hard Way” tutorial by Kelsey Hightower (which is more than great, by the way!). The Why K8s is so complicated discussions have been popping up here and there for years already.
Here are some articles reflecting what people think about Kubernetes’ complexity:
- How do you respond when people say that Kubernetes is too complicated? (Reddit, Jan’2023);
- Kubernetes is complex because you want complex things (by Natan Yellin from Robusta, Apr’2022);
- Two reasons Kubernetes is so complex (by Nelson Elhage from Anthropic, Jan’2022);
- Why is Kubernetes So Damn Complicated? (by Tennis Smith from Appvia, Nov’2021);
- Kubernetes’ Complexity (by Jeff Geerling from Acquia, Jun’2018).
And what are your thoughts? Is there anything you would like to change about the iceberg? Feel free to share your feelings and suggestions in the comments below!

Comments