

The customer clusters we maintain have both single-instance Redis®* installations — usually for caches that we’re safe if we lose — as well as more fault-tolerant solutions, such as Redis Sentinel or Redis Cluster. Based on our experience, in all three cases, you can seamlessly migrate from Redis to its alternative, KeyDB, and enjoy the performance gains that result. Since this project is a multi-threaded fork of Redis, it helps your workloads get rid of the Redis bottleneck of being limited to a single processor core. (While Redis has introduced I/O support in separate threads in newer versions, sometimes that doesn’t quite cut it.)
That said, if we intend to use fault-tolerant solutions like Sentinel and Cluster, we will need these technologies to be supported by the library that the application uses to connect to Redis. However, few libraries can read from those Redis replicas — as in both cases (Sentinel and Cluster), you usually read from masters. The same is obviously true for writing.
So we end up with multiple replicas relying on fairly expensive in-memory storage, but only a fraction of them are constantly utilized, while the rest play a purely supportive role. However, in the majority of cases, in-memory NoSQL DB operations are read operations.
On the other hand, KeyDB comes with two killer features — Active Replica and Multi-Master modes. These configurations deliver a distributed fault-tolerant KeyDB setup, i.e. in-memory replicated DB (IMDB) that is compatible with Redis. With them, you can write to and read from any node you wish. Most importantly, from an application perspective, all this appears as a single Redis instance without any Sentinel intervention — meaning you don’t have to change anything in the application code.
Sounds fantastic, doesn’t it? Now let’s see how it all works in practice. First, we’ll explore Active Replica and Multi-Master configuration modes, and then we’ll share a few real case studies from our experience running actual applications based on Redis or, consequently, KeyDB as its drop-in replacement.
Previously, we already covered two successful migrations to KeyDB in production (story 1, story 2) and explained how it made our lives easier.
1. How Active Replica works in KeyDB
In short, Active Replica allows you to have multiple KeyDB replicas available for reading and writing. Data written to any replica is replicated to all other replicas in the chain (if any) — as opposed to Redis, where data written to a replica in replica-read-only=false mode is not replicated.
Also note that since Redis 4.0 replica writes are only local, and are not propagated to sub-replicas attached to the instance. Sub-replicas instead will always receive the replication stream identical to the one sent by the top-level master to the intermediate replicas. So for example in the following setup:
A ---> B ---> CEven if B is writable, C will not see B writes and will instead have identical dataset as the master instance A.
In the most degenerate case of a replication chain with active-replica yes, there are two instances, each of which being a replica of the other.
What does such a configuration bring to the table?
- Well, it turns out that the application can work with any IMDB (in-memory database) instance as if it were “regular Redis”.
- The reading load is shared between the two instances, and you don’t need to make any changes to the application or library code (while using a simple DNS or service-based load balancer in Kubernetes).
- Automatic and seamless switching (failover) between replicas is supported.
- KeyDB instances can be maintained whenever you want simply by making changes to the DNS or, if the services are running in Kubernetes, by performing a rolling update of the KeyDB pods.
A look under the hood
To enable Active Replica, set the active-replica parameter to yes. This will automatically set replica-read-only to no and allow write operations to be performed on that replica.
Let’s say we have two servers, A and B, both running as Active Replicas:
- Run the
replicaof [A address][A port]command on server B. This will result in B deleting its database and fetching the data from A. - Next, run the
replicaof [address B] [port B]command on server A. This will result in A deleting its database and fetching the data from B, including the data it transferred to B in the previous step. - Now both servers will pass their records to each other.
From now on, writes can be made to any of the KeyDB instances, even if connectivity between them is temporarily lost. Once connectivity is restored, each node will attempt to download the changes from the linked node. Every record has a timestamp (indicating when the key change took place), so if the same key was changed in both instances when there was no connectivity between them, the most recent value will be used.
The main drawback of Active Replica mode
Suppose we create a chain of more than two KeyDBs to distribute read operations but are still able to write to any of the instances. In this case, each instance would become a point of failure that could easily gridlock replication as data is only moving through the ring in one direction.
A ---> B ---> C
^ |
----- D <----2. How Multi-Master works in KeyDB
Multi-Master mode eliminates the issue described above. Essentially, it allows each KeyDB instance to connect to more than one master and fetch changes from each of them. As with Active Replica, the write timestamp is used to resolve conflicts — the most recent key will be written to the replica.
A look under the hood
With this mode enabled (multi-master set to yes), when connecting to a master, the replica does not delete all of its data but adds the data received over the replication channel from each of the masters based on timestamps.
Suppose we have a KeyDB instance running with the following options: --multi-master yes --replicaof 192.168.0.1 6379 --replicaof 192.168.0.2 6379.
First, KeyDB will read the local rdb file (if there is one). It will then connect to both masters and try to perform either partial (if there has previously been replication from this master) or full data replication from them. This will result in the replica having a superposition of three sources: the local data and the data from both masters (with the most recent keys based on a timestamp).
What does such a configuration bring to the table?
- In this case, a KeyDB instance can connect to multiple masters simultaneously and fetch updates from all of them (unlike regular Redis, which can only connect to a single master).
- Just like with Active Replica, in Multi-Master mode, the application treats any KeyDB instance as if it were a “regular Redis” one, meaning it can read data from it or write data to it (while Active Replica mode is enabled).
3. The best of both worlds: Multi-Master + Active Replica
The mode in which Multi-Master and Active Replica are enabled simultaneously is the most promising, as it allows you to implement complex data replication schemes between KeyDB instances. On top of that, this mode allows you to perform various manipulations on any of the instances.
Earlier, we described the way the data transfer ring between KeyDB instances operates in Active Replica mode. Adding Multi-Master to this scheme lets you fire up a bidirectional ring that is more robust and resistant to node failures (we’ll discuss the full-mesh topology variant below).

Here’s a Docker Compose example with a cluster of three Multi-Master + Active Replica KeyDB instances:
version: '3.8'
services:
keydb-0:
image: eqalpha/keydb:alpine_x86_64_v6.3.3
hostname: keydb-0
command: keydb-server --active-replica yes --multi-master yes --replicaof keydb-1 6379 --replicaof keydb-2 6379
keydb-1:
image: eqalpha/keydb:alpine_x86_64_v6.3.3
hostname: keydb-1
command: keydb-server --active-replica yes --multi-master yes --replicaof keydb-0 6379 --replicaof keydb-2 6379
keydb-2:
image: eqalpha/keydb:alpine_x86_64_v6.3.3
hostname: keydb-2
command: keydb-server --active-replica yes --multi-master yes --replicaof keydb-0 6379 --replicaof keydb-1 6379Looks like we’ve finally found the silver bullet. Speed, replication, multi-threading, replica failover in case of the master’s failure — and all this in a fashion transparent to an application accustomed to dealing with regular Redis! But in practice, we encountered a bunch of not-so-obvious issues, which we’ll discuss below.
Case #1: Tricky increment
KeyDB in Multi-Master + Active Replica mode stores and replicates keys quite well — after all, it is a key-value database. However, there are many other commands besides the usual SET and GET. The results of running them in Multi-Master mode might surprise you.
Let’s, for example, look at a basic INCR command that increments the value of a key by 1. Suppose there are two nodes in different data centers, with each node being a replica of the other.
- Let’s run the following command on one of the nodes:
SET mykey 1. The key value is propagated to the second node, causingmykeyto have a value of 1 everywhere. - Now let’s break the connection between the two nodes (mimicking a temporary network failure between the data centers) and:
- run
INCR mykeythree times on the first node. The value ofmykeywill be 4; - run
INCR mykeyonce on the second node, increasing the value ofmykeyto 2.
- run
- Now, restore the connection between the nodes. What will happen?
We will end up with mykey being set to 2 on both nodes since it is the key values (not the operations) that are synchronized, and the key with a value of 2 has a more recent timestamp.
Hardly what you were expecting, right? Running other commands may lead to unexpected results as well.
Case #2: Out of memory
One day, we decided to deploy a highly fault-tolerant KeyDB installation in two Kubernetes clusters located in two different data centers. We opted for KeyDB in Multi-Master + Active Replica mode because even if the connection between the data centers were lost, we would still have readable/writeable in-memory storage.
With this configuration, applications can safely continue to write to and read data from both clusters. That is, they won’t notice any issues (we used KeyDB for caching). We would end up with a cache “spread” across two data centers rather than two separate caches.
The issue discussed in the first case above didn’t bother us, as the applications were sending and processing only SET and GET requests. In this case, once the connection was restored, the KeyDB instances would simply synchronize with each other, and the newest values would end up in the cache.
We created three KeyDB instances in each data center, with each instance having five masters (two in its own DC and three in a neighboring DC). Thus, each instance was a master for five replicas. KeyDB instances were run in the Kubernetes cluster as a StatefulSet, and applications could only connect through the Service to their local instances. KeyDB automatically synchronized the data stored in one of the clusters with the other cluster.
Once the system was set up, we did some testing:
- We restarted and shut down some of the containers.
- We broke connections between data centers and then performed read and write operations in a partitioned cluster.
- We did some load testing for the application.
Things were looking good. KeyDB was quickly syncing after a restart, and the read load was evenly distributed between the pods, which was delightful for us (it is hard to achieve that with Redis Sentinel).
After successful testing, we couldn’t wait to put our configuration to work. However, during the next scheduled load testing, we encountered an unexpected situation — one of the KeyDB pods had crashed. It would seem there was nothing to worry about. The Kubernetes service would automatically withdraw this pod from load balancing and reroute the requests to the remaining two KeyDB pods in the cluster. This is exactly what the replication scheme was built for, after all! But then something strange happened:
- The app became painfully unresponsive, with the cache apparently being the problem.
- The crashed KeyDB pod kept crashing on OOM and could not restart.
Hmmm!.. What’s going on?
- In Multi-Master mode, the pod tried to replicate from five of its instances at the same time in an attempt to restart, thus hugely overloading the network. During testing, this problem could not be detected since there was almost no data in the cache.
- In the end, this pod was getting a lot of new keys that had changed during its downtime: it saved them and rebroadcast them to its replicas. That is, to those other five masters! In doing so, it further stressed the network and the CPUs of neighboring replicas that were broadcasting
RREPLAY. - As data from all the replicas were copied simultaneously, memory consumption increased dramatically compared to the normal state, and the container was constantly getting killed due to being OOM (out of memory).
To put it in numbers: the container was normally allocated 3 GB of RAM, and the amount of data in KeyDB was 2 GB. At startup, this 2 GB was first read from the rdb file, and then the container fetched 2 GB from each of the neighboring five master nodes (i.e., 10 GB). As a result, the system was trying to process all this information and inevitably exceeded the set limit of 3 GB.
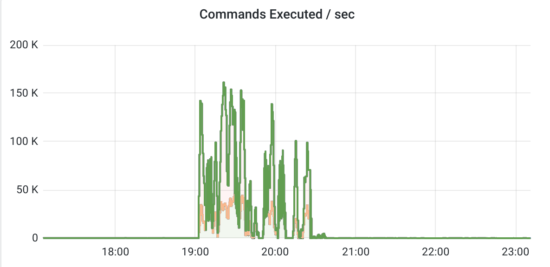
By comparison, applications were writing data to KeyDB just at tens of operations per second. The explosive growth of commands that actually brought the service down was caused by resynchronization.
So, here’s what we had initially:

We revamped this scheme to reduce cross-replication while retaining useful things like inter-cluster and intra-cluster fault tolerance:
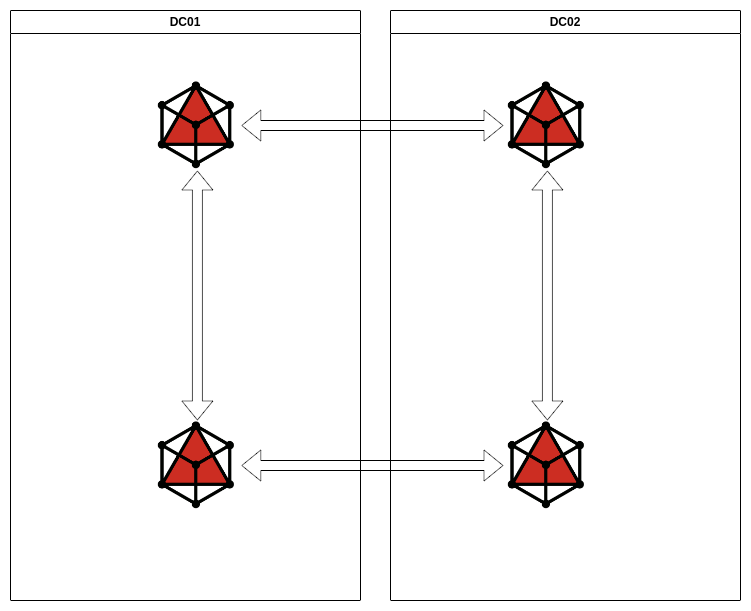
In the new scheme, replication persisted even if any of the nodes failed, as it was bidirectional. This reduced the number of RREPLAYs, but they were still popping up en masse during node synching.
After rereading the KeyDB documentation (namely, the config file on GitHub), we found a promising multi-master-no-forward parameter:
# Avoid forwarding RREPLAY messages to other masters?
# WARNING: This setting is dangerous! You must be certain all masters are connected to each
# other in a true mesh topology or data loss will occur!
# This command can be used to reduce multimaster bus traffic
# multi-master-no-forward noDespite the warning, we thought this was the parameter we needed. After all, we initially built a full mesh, and we didn’t need a rebroadcast since all KeyDB nodes were connected to each other.
Thus we ended up reverting to a full-mesh scheme, only with the --multi-master-no-forward yes option enabled.

As we can see now, KeyDB has quite a wide range of options for configuring replication, and these options allow you to build various complex schemes. However, not all configurations can fit your workloads — merely recovering from a single node crash may entail unexpected consequences.
Case #3: Node.js libraries keep us busy
We believe one of the crucial KeyDB features is to have replicated Redis-compatible storage. The nice thing about it is that the application will think it’s dealing with a regular Redis instance. This means you don’t need to modify your application when migrating to KeyDB. If it works with Redis, it will work with KeyDB. You don’t need to make any code changes — as opposed to working with Redis Cluster or Sentinel. (By the way, in order to work with Sentinel without modifying the application, there’s a clever trick we use — redis-sentinel-proxy.)
However, it turned out there are some complications associated with replication. You still probably have Case #1 (above) fresh in your memory, but there shouldn’t be any problems with regular GET and SET requests, right? Unless… But let’s not skip ahead!
Backstory
There is a KeyDB StatefulSet running in Kubernetes with the similar-to-following configuration:
The Node.js app uses it as a cache. However, during rolling updates, the app’s performance degrades catastrophically. We repeatedly checked our chart but to no avail:
- During the rolling update, the pod is first excluded from load balancing.
- The
PreStophook then waits for a while and terminates the KeyDB container. - After startup, a container is expected to start, synchronize its data, and only then the
readinessProbeshould include it in load balancing. - And while one of the containers is being restarted, the other two continue to process app requests.
We used Redis CLI SET/GET to figure out what was going on and found no signs of degradation. Yet the issue persisted: the application did not run smoothly during pod restarts (or in the case one of the pods failed to start due to a lack of resources in the cluster). But why?
We discovered an anomaly — the moment an application is “down”, the number of INFO requests in the KeyDB metrics jumps dramatically. As it turned out, those were app requests. We contacted the development team to ask about the large number of INFO requests. They replied that they don’t do any INFOs, but use the nuxt-perfect-cache library to handle the cache, which “just works”. Further investigation revealed that nuxt-perfect-cache leverages the node-redis library, which, when connected to a KeyDB instance, uses the INFO command to find out whether the instance is ready.
An excerpt from the documentation:
When a connection is established to the Redis server, the server might still be loading the database from the disk. While loading, the server will not respond to any commands. To work around this, Node Redis has a “ready check” which sends the
INFOcommand to the server. The response from theINFOcommand indicates whether the server is ready for more commands. When ready,node_redisemits areadyevent. Settingno_ready_checktotruewill inhibit this check.
You can override such behavior in node-redis via the no_ready_check option (it is set to false by default), whereas in nuxt-perfect-cache you cannot override the value for the node-redis library used under the hood.
That is, when the application connects to Redis (or KeyDB in our case), it checks whether replication is complete. If not, it waits for a while and repeats the INFO request without even trying to read the data. But this method of checking replication status using INFO, which works well in Redis, is not suitable for KeyDB, because in the latter, you can read (and write) to a replica that failed to connect to the master.
As a result, while we have two of the three Multi-Master KeyDB replicas fully synchronized, the application still refuses to work with them because it checks master_link_status using INFO requests before even attempting to read from the KeyDB instance. The funny thing is that if Redis is not available at all, the application falls back to using no cache, and the response time increases from 300 ms to 500 ms. In contrast, if it hits a Multi-Master KeyDB lacking one of the masters, it enters into an infinite INFO loop.
The same issue also plagues other Node.js cache libraries that rely on Redis Node.js (e.g., cache-manager-redis-store).
Case #4: Is KeyDB replication reliable enough?
Performance tests of a single-instance KeyDB against a single-instance Redis show that KeyDB is at least as good as the competitor. Unfortunately, replication turns this rosy scenario on its head.
Let’s do some testing. To do so, we’ll use a laptop with an i5-11300H processor; the service and the benchmark will run on their dedicated cores.
Let’s insert 8 KB keys into the Redis database.
Contents of the docker-compose.yaml file:
version: '3.8'
services:
redis-0:
image: redis:6.2.12
hostname: redis-0
command: redis-server --maxmemory 500mb --maxmemory-policy allkeys-lru --io-threads 4
cpuset: 0-3
bench:
image: redis:6.2.12
hostname: bench
command: bash -c 'sleep 5; redis-benchmark --threads 2 -r 100000000 -n 1000000 -d 8192 -t set -h redis-0'
cpuset: 6,7The results are:
bench_1 | Summary:
bench_1 | throughput summary: 147950.89 requests per second
bench_1 | latency summary (msec):
bench_1 | avg min p50 p95 p99 max
bench_1 | 0.196 0.024 0.183 0.263 0.399 85.951Let’s now do the same with KeyDB.
Contents of the docker-compose.yaml file:
version: '3.8'
services:
keydb-0:
image: eqalpha/keydb:alpine_x86_64_v6.3.3
hostname: keydb-0
command: keydb-server --maxmemory 500mb --maxmemory-policy allkeys-lru --server-threads 4
cpuset: 0-3
bench:
image: redis:6.2.12
hostname: bench
command: bash -c 'sleep 5; redis-benchmark --threads 2 -r 100000000 -n 1000000 -d 8192 -t set -h keydb-0'
cpuset: 6,7The results appear more or less the same (within the margin of error):
bench_1 | Summary:
bench_1 | throughput summary: 142592.33 requests per second
bench_1 | latency summary (msec):
bench_1 | avg min p50 p95 p99 max
bench_1 | 0.216 0.032 0.207 0.295 0.407 24.271Now let’s add replication to the equation.
Redis (replicated)
Contents of our new docker-compose.yaml file:
version: '3.8'
services:
redis-0:
image: redis:6.2.12
hostname: redis-0
command: redis-server --maxmemory 500mb --maxmemory-policy allkeys-lru --io-threads 4
cpuset: 0-3
redis-1:
image: redis:6.2.12
hostname: keydb-1
command: redis-server --replicaof redis-0 6379 --maxmemory 500mb --maxmemory-policy allkeys-lru --io-threads 4
cpuset: 4-7
bench:
image: redis:6.2.12
hostname: bench
command: bash -c 'sleep 5; redis-benchmark --threads 2 -r 100000000 -n 1000000 -d 8192 -t set -h redis-0'
cpuset: 6,7New results:
bench_1 | Summary:
bench_1 | throughput summary: 92833.27 requests per second
bench_1 | latency summary (msec):
bench_1 | avg min p50 p95 p99 max
bench_1 | 0.436 0.072 0.415 0.639 0.751 24.191KeyDB (replicated)
Contents of our new docker-compose.yaml file:
version: '3.8'
services:
keydb-0:
image: eqalpha/keydb:alpine_x86_64_v6.3.3
hostname: keydb-0
command: keydb-server --active-replica no --multi-master no --maxmemory 500mb --maxmemory-policy allkeys-lru --server-threads 4
cpuset: 0-3
keydb-1:
image: eqalpha/keydb:alpine_x86_64_v6.3.3
hostname: keydb-1
command: keydb-server --active-replica no --multi-master no --replicaof keydb-0 6379 --maxmemory 500mb --maxmemory-policy allkeys-lru --server-threads 4
cpuset: 4-7
bench:
image: redis:6.2.12
hostname: bench
command: bash -c 'sleep 5; redis-benchmark --threads 2 -r 100000000 -n 1000000 -d 8192 -t set -h keydb-0'
cpuset: 6,7New results:
bench_1 | Summary:
bench_1 | throughput summary: 56934.64 requests per second
bench_1 | latency summary (msec):
bench_1 | avg min p50 p95 p99 max
bench_1 | 0.808 0.040 0.383 0.815 10.583 201.983KeyDB got a much lower throughput this time. Why is that? The problem is keydb-1 cannot replicate data from keydb-0 at the same rate as we write it there by the benchmark. In the process, it creates several resync attempts, crashes, and once the benchmark is over, it does a full resync with the master.
Container logs:
keydb-0_1 | 1:20:M 11 Jun 2023 10:39:18.532 # Replication backlog is too small, resizing to: 2097152 bytes
keydb-0_1 | 1:22:M 11 Jun 2023 10:39:18.537 # Replication backlog is too small, resizing to: 4194304 bytes
keydb-0_1 | 1:22:M 11 Jun 2023 10:39:18.543 # Replication backlog is too small, resizing to: 8388608 bytes
keydb-0_1 | 1:24:M 11 Jun 2023 10:39:18.557 # Replication backlog is too small, resizing to: 16777216 bytes
keydb-0_1 | 1:22:M 11 Jun 2023 10:39:18.612 # Replication backlog is too small, resizing to: 33554432 bytes
keydb-0_1 | 1:24:M 11 Jun 2023 10:39:18.668 # Replication backlog is too small, resizing to: 67108864 bytes
keydb-0_1 | 1:22:M 11 Jun 2023 10:39:18.788 # Replication backlog is too small, resizing to: 134217728 bytes
keydb-0_1 | 1:22:M 11 Jun 2023 10:39:19.041 # Replication backlog is too small, resizing to: 268435456 bytes
keydb-0_1 | 1:24:M 11 Jun 2023 10:39:20.192 # Client id=6 addr=172.31.0.3:41086 laddr=172.31.0.4:6379 fd=28 name= age=7 idle=0 flags=S db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=40954 argv-mem=0 obl=0 oll=0 omem=268427868 tot-mem=268489332 events=rw cmd=replconf user=default redir=-1 scheduled to be closed ASAP due to exceeding output buffer hard limit.
keydb-0_1 | 1:20:M 11 Jun 2023 10:39:20.193 # Connection with replica 172.31.0.3:6379 lost.
keydb-1_1 | 1:22:S 11 Jun 2023 10:39:20.199 # Connection with master lost.
keydb-1_1 | 1:22:S 11 Jun 2023 10:39:20.199 * Caching the disconnected master state.
keydb-1_1 | 1:22:S 11 Jun 2023 10:39:20.199 * Reconnecting to MASTER keydb-0:6379
keydb-1_1 | 1:22:S 11 Jun 2023 10:39:20.199 * MASTER <-> REPLICA sync started
keydb-1_1 | 1:22:S 11 Jun 2023 10:39:20.199 * Non blocking connect for SYNC fired the event.
keydb-1_1 | 1:22:S 11 Jun 2023 10:39:20.200 * Master replied to PING, replication can continue...
keydb-1_1 | 1:22:S 11 Jun 2023 10:39:20.201 * Trying a partial resynchronization (request 4d55fe87f41c7ae358bc7c4c2c90379283d1b7fa:1123521824).
keydb-0_1 | 1:20:M 11 Jun 2023 10:39:20.201 * Replica 172.31.0.3:6379 asks for synchronization
keydb-0_1 | 1:20:M 11 Jun 2023 10:39:20.201 * Unable to partial resync with replica 172.31.0.3:6379 for lack of backlog (Replica request was: 1123521824).
keydb-0_1 | 1:20:M 11 Jun 2023 10:39:20.201 * Starting BGSAVE for SYNC with target: disk
keydb-0_1 | 1:20:M 11 Jun 2023 10:39:20.211 * Background saving started by pid 27
keydb-0_1 | 1:20:M 11 Jun 2023 10:39:20.211 * Background saving started
keydb-1_1 | 1:22:S 11 Jun 2023 10:39:20.211 * Full resync from master: 4d55fe87f41c7ae358bc7c4c2c90379283d1b7fa:1401369952
keydb-1_1 | 1:22:S 11 Jun 2023 10:39:20.211 * Discarding previously cached master state.
keydb-0_1 | 1:22:M 11 Jun 2023 10:39:20.716 # Client id=58 addr=172.31.0.3:48260 laddr=172.31.0.4:6379 fd=28 name= age=0 idle=0 flags=S db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 argv-mem=0 obl=0 oll=0 omem=0 tot-mem=20512 events=r cmd=psync user=default redir=-1 scheduled to be closed ASAP due to exceeding output buffer hard limit.
keydb-0_1 | 1:20:M 11 Jun 2023 10:39:20.716 # Connection with replica 172.31.0.3:6379 lost.
keydb-0_1 | 1:20:M 11 Jun 2023 10:39:20.768 * Reclaiming 267386880 replication backlog bytesThis problem does not manifest itself (in the test installation) if KeyDB manages to synchronize the data. For example, if the key size used in the benchmark is the standard 3 bytes rather than 8 KB, or if the RPS is merely in the thousands rather than in the tens of thousands of SET operations per second. However, all other things being equal, Redis manages to synchronize without replication crashes, while KeyDB does not.
Playing around our KeyDB setup
Let’s fix this problem by increasing the client-output-buffer-limit on the master (config set client-output-buffer-limit "slave 836870912 836870912 0") and run the test again.
In our latest docker-compose.yaml, we will only change the command parameter in the bench section to the following one:
command: bash -c 'sleep 5; redis-cli -h keydb-0 config set client-output-buffer-limit "slave 836870912 836870912 0"; redis-benchmark --threads 2 -r 100000000 -n 1000000 -d 8192 -t set -h keydb-0'Results:
bench_1 | Summary:
bench_1 | throughput summary: 97370.98 requests per second
bench_1 | latency summary (msec):
bench_1 | avg min p50 p95 p99 max
bench_1 | 0.462 0.056 0.415 0.759 0.951 96.895KeyDB comes out ahead this time! At least it caught up and surpassed Redis a bit.
A much more unpleasant thing will happen if you run the same benchmark without increasing the buffer with KeyDB in Active Replica mode. The replica will still be unable to sync the data with the master and will end up in an infinite resynchronization loop.
The corresponding docker-compose.yaml will be:
version: '3.8'
services:
keydb-0:
image: eqalpha/keydb:alpine_x86_64_v6.3.3
hostname: keydb-0
command: keydb-server --active-replica yes --multi-master no --replicaof keydb-1 6379 --maxmemory 500mb --maxmemory-policy allkeys-lru --server-threads 4
cpuset: 0-3
keydb-1:
image: eqalpha/keydb:alpine_x86_64_v6.3.3
hostname: keydb-1
command: keydb-server --active-replica yes --multi-master no --replicaof keydb-0 6379 --maxmemory 500mb --maxmemory-policy allkeys-lru --server-threads 4
cpuset: 4-7
bench:
image: redis:6.2.12
hostname: bench
command: bash -c 'sleep 5; redis-benchmark --threads 2 -r 100000000 -n 1000000 -d 8192 -t set -h keydb-0'
cpuset: 6,7To see how consistent KeyDB replication is when Active Replica mode is enabled, we will modify our command in bench for the very last time:
command: bash -c 'sleep 5; echo "Start bench"; redis-benchmark --threads 2 -r 100000000 -n 1000000 -d 512 -t set -h keydb-0'
As the container logs suggest, the test completes without any errors:
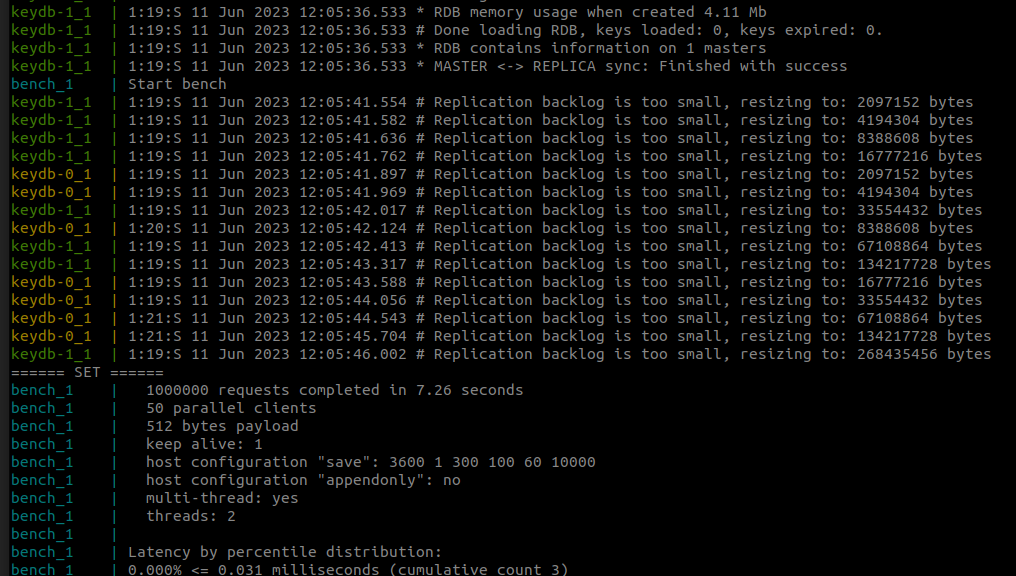
Let’s check our databases:
docker exec -it keydb_keydb-0_1 keydb-cli DBSIZE
(integer) 706117
docker exec -it keydb_keydb-1_1 keydb-cli DBSIZE
(integer) 710368The resulting number of keys differs between instances! But if Active Replica mode is disabled, the number of keys in the master and in the replica is the same for all tests.
It is worth noting that for 10-20 thousand SET operations per second (which, admittedly, is quite a lot), we could not reproduce the desynchronization problem. As it turns out, replication in KeyDB is not very reliable. This can lead to catastrophic consequences under really high write loads. Still, we continue to explore the replication issue to achieve the result we are looking for.
Once again, we have confirmed that there is no silver bullet for new technologies. Problems can trip you up in completely unexpected places.
Our takeaways
- As we have learned, KeyDB in Multi-Master + Active Replica mode works well under moderate loads.
- If using a full-mesh connection between KeyDB nodes, you must pay attention to inter-node traffic, which can be surprisingly high.
- Migrating to KeyDB can create problems for applications that use “overly smart” libraries (such as node-redis) to interact with in-memory databases.
- For high-load, write- and read-intensive applications, you should probably stick to a classic Redis cluster. This may require making additional changes to the application code, library tuning, etc.
* Redis is a registered trademark of Redis Ltd. Any rights therein are reserved to Redis Ltd. Any use by Palark GmbH is for referential purposes only and does not indicate any sponsorship, endorsement or affiliation between Redis and Palark GmbH.

Hello,
I’m trying to implement something similar. But for my application, I am noticing straight-up performance depreciation with keyDB. There’s no special difference in my configuration between redis and keyDB, only that keyDB is using 4 threads while redis is using 1.
The multiple-master and active-replica combination of keydb is giving worse performance. I am able to do much better with two isolated redis instances balanced by round-robin selection.
Safe to conclude keyDB won’t work for me? Is there anything I am missing?
Hi!
Does this mean you use Redis for caching or similar needs? In this case, it seems you might skip the entire replication mess (the Active Replica feature) as such. Do you really need to have all your new entries written in one instance appearing in another one? You can also switch your Redis to KeyDB with no replication enabled, which might improve your performance (it depends on specific cases, though).
Hello,
I’m trying to replicate the master-replication and active-replication evaluation, but I’m having memory problem with the backlog when I do the active-replication evaluation.
The two instances are on different machines. I’m using an HAProxy that is configured on a separate machine (round-robin loadbalancer configured). When the benchmark goes over 55% of execution it consumes all the memory allocated to the backlog (90gb) and I start getting error messages in the benchmark like the one I show: handle error response: -LOADING KeyDB is loading the dataset in memory.
Do you know if there is any configuration that allows to free memory used by the backlog? Did you have the same problem?
Thank you very much,
Ainhoa
Hi Ainhoa!
As I clarified with the author of this article, he hadn’t experienced such an issue. However, he seemed to have a significantly smaller setup.
As for the problem itself, I don’t think cleaning your backlog is a good idea (it can be destructive for the replication?). These configuration settings (i.e.
repl-backlog-ttlandrepl-backlog-size) might be helpful for your case — personally, we haven’t tried them yet, though.