

RabbitMQ is a message broker written in Erlang. It allows you to build a failover cluster with full data replication to several nodes where each node can handle read and write requests. Having a lot of Kubernetes clusters in production, we maintain a large number of RabbitMQ instances. A while back we were confronted with the need to migrate data from one RMQ cluster to another with zero downtime.
It was needed in at least two scenarios:
- Transfer of data from the RabbitMQ cluster outside of Kubernetes to the new cluster operating within the K8s pods.
- Migration of the RabbitMQ cluster from one Kubernetes namespace to another (e.g. moving the infrastructure of application from staging to production).
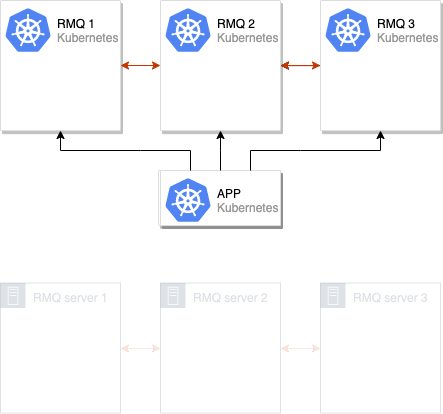
The method proposed in this article is focused on situations (but certainly not limited to them) when an old RabbitMQ cluster (e.g. consisting of 3 nodes) is either deployed to K8s or located on some old servers. It is used by an application already deployed to Kubernetes (or to be deployed to K8s):
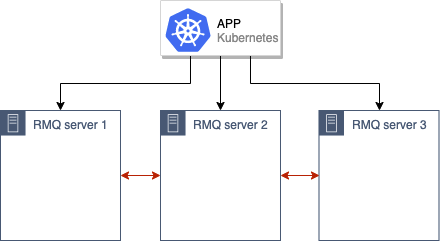
Our goal is to migrate this old RMQ cluster to the new production environment in Kubernetes.
We would start with a general approach to the migration itself and then we’ll provide technical details of its implementation.
Migration algorithm
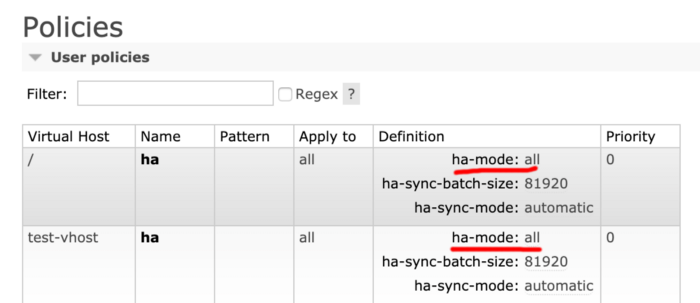
The preliminary phase before any action is to ensure that the old installation of RabbitMQ has the High Availability mode (HA) enabled. The reasoning behind this is obvious: we do not want to lose any data. In order to check it go to the RabbitMQ admin panel and in the Admin → Policies tab make sure that the parameter ha-mode: all is set:
Next step is to create a new RabbitMQ cluster running in Kubernetes pods (in our case it consists of 3 nodes, however, their number may vary).
Then we merge old and new RabbitMQ clusters getting a single cluster containing 6 nodes:
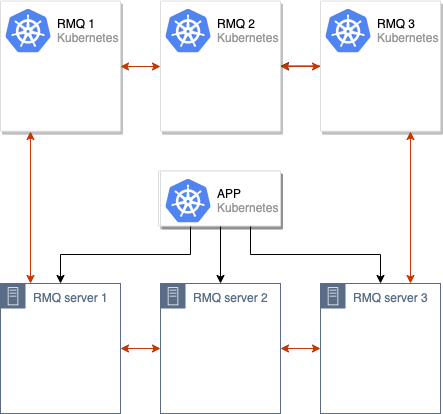
The process of data synchronization between old and new RabbitMQ clusters begins. When all data is synchronized between cluster nodes, we can switch the application to the new cluster:
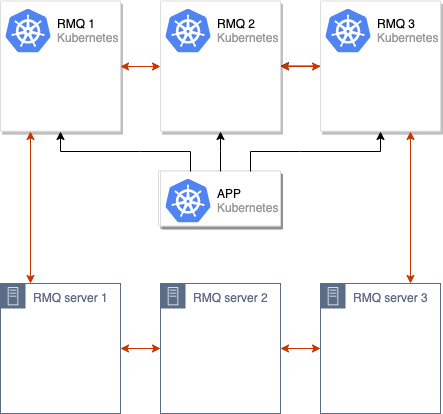
Once the switchover is complete, we can deactivate old RabbitMQ nodes and we are done:
We have repeatedly used this scheme with production environments. For our own convenience, we have implemented it as a part of our internal system that distributes typical RMQ configurations to multiple Kubernetes clusters. However, the specific instructions provided below are for anyone who wants to try this solution in action — you may easily apply them to your own installations.
Practical Implementation
Prerequisites
The requirements are simple. You will need:
- A Kubernetes cluster (Minikube-based cluster would suffice);
- A RabbitMQ cluster (deployed on either bare-metal servers or Kubernetes via the official Helm chart).
In our example, we will imitate our existing RMQ cluster deploying it on Kubernetes and calling it rmq-old.
Preparing our old RMQ installation
1. Download Helm chart:
helm fetch --untar stable/rabbitmq-ha… and slightly modify it. Set a password, an ErlangCookie and define the ha-all policy for convenience. In this case, the queues would synchronize in all nodes of the RMQ cluster by default:
rabbitmqPassword: guest
rabbitmqErlangCookie: mae9joopaol7aiVu3eechei2waiGa2we
definitions:
policies: |-
{
'name': 'ha-all',
'pattern': '.*',
'vhost': '/',
'definition': {
'ha-mode': 'all',
'ha-sync-mode': 'automatic',
'ha-sync-batch-size': 81920
}
}2. Install the chart:
helm install . --name rmq-old --namespace rmq-old3. Go to the RabbitMQ admin page, create a new queue and add several messages to it. We need them to make sure that everything would go smoothly and we won’t lose anything during the migration:

Our old RMQ cluster with data that need to be transferred is ready.
Migration of the RabbitMQ cluster
1. Firstly, deploy a new RabbitMQ cluster in a different namespace with the same ErlangCookie and user password. To do this, perform the actions described above and substitute the final installation command with the following:
helm install . --name rmq-new --namespace rmq-new2. Now you have to merge new cluster with old one. To do this, enter every pod of new RabbitMQ cluster and execute the following commands:
export OLD_RMQ=rabbit@rmq-old-rabbitmq-ha-0.rmq-old-rabbitmq-ha-discovery.rmq-old.svc.cluster.local &&
rabbitmqctl stop_app &&
rabbitmqctl join_cluster $OLD_RMQ &&
rabbitmqctl start_appOLD_RMQ variable used here specifies the address of one of old RMQ cluster’s nodes. Thus, commands listed above would stop the current node of the new RMQ cluster, connect it to the old cluster and restart it.
3. The RMQ cluster containing 6 nodes is ready:

Now we have to wait until the messages are synchronized between all nodes. As you might easily guess, the speed of synchronization depends on the hardware and the number of messages. In our case, there are only 10 of them, so the synchronization is instantaneous (with a sufficiently large number of messages the synchronization could take hours).
The synchronization status:

Here, +5 means that messages are already replicated to 5 more nodes (in addition to the one stated in the Node field). Thus, the synchronization was successful.
4. Now it is time to set the new RMQ address in your application (what you need to do here depends on how your application is configured) and to say goodbye to the old cluster.
The last step (i.e. after switching the application to the new cluster) is to enter each node of the old cluster and execute the following commands:
rabbitmqctl stop_app
rabbitmqctl resetNow the RMQ cluster will “forget” about old nodes. Congrats, your migration process is over!
Note: If you use certificates with your RMQ, the migration process is carried out in the same way.
Conclusion
The described scheme is suitable for all cases when there is a need to transfer RabbitMQ or just to move to a new cluster.
We encountered difficulties with this approach only once. In that case requests to RMQ came from many places, and we did not have the opportunity to switch the RMQ address to the new one everywhere. We developed the following solution: we started a new RMQ instance in the same namespace with identical labels so it could be used by the existing services and Ingresses. Then, just after the pod had started, we manually deleted labels so that the empty RMQ would not get the requests, and added them back after the synchronization was complete.
We have applied the same strategy during the RabbitMQ upgrade to a new version with a modified configuration — everything went smoothly.

Hi,
I have an external RabbitMQ and i want to join new nodes on K8s to this node. They both share the erlang cookie.
How did you solve the networking problems? did you expose all the needed ports of each pod?
I have:
server1 with cluster rabbit@mycluster
Then i deployed cluster operator and i got in the pod the RabbitMQ nodename, and from the POD i ran:
$ rabbitmqctl join_cluster rabbit@disrmqs11
Clustering node rabbit@rabbitmq-sandbox-server-0.rabbitmq-sandbox-nodes.rabbitmq-system with rabbit@mycluster
is it possible that the external nodes needs to talk to the POD via port 4369?
Hi Andres!
In this article, individual services were created for each RabbitMQ pod in Kubernetes. For AWS, a LoadBalancer was created for each pod (on the same ports). In the case of bare-metal server, they were added to /etc/hosts. On top of that, relevant bare-metal server’s entries were added to /etc/hosts of each pod in Kubernetes.
The engineer confirmed he didn’t find an option to specify ports in the
rabbitmqctl join_clustercommand meaning you really need to have network accessibility between both clusters using the default ports.Great article!
We are attempting to migrate an external RabbitMQ cluster into K8S ourselves too. We’ve followed you guide, however, when running the `rabbitmqctl join_cluster` command, we are facing the following issue:
* TCP connection succeeded but Erlang distribution failed
We’ve double-checked the Erlang cookies on both sides and they do match. Our assumption is that the external nodes are using short hostnames – thus we’re unable to resolve them from K8S.
Another possible problem might be that the external RabbitMQ cluster is not able to communicate with the pods running inside K8S. Have you faced anything similar when migrating external RMQ clusters into K8S?
Thank you for your time!
Hi Attila! We have never experienced such an issue and sadly have no apparent idea of what can cause it.