 SRE as a Service
SRE as a Service DevOps as a Service
DevOps as a Service Cloud & Kubernetes migration
Cloud & Kubernetes migration Infrastructure & CI/CD audit
Infrastructure & CI/CD audit R&D and technology consulting
R&D and technology consulting Kubernetes support
Kubernetes support Solution for SaaS
Solution for SaaS All services
All services

This article discusses the so-called review environments running in Kubernetes clusters. Why are these environments necessary and what are typical use cases for them? How to make a review environment pipeline in GitLab CI/CD? What potential problems can arise, and how to avoid them?
Review environments. What are they used for?
Overview
First, let me start by saying a few words about what an environment is. An environment (or deployment environment, sometimes also referred to as a tier) is where the application is deployed and run with a specific configuration that can be different from production. Usually, each environment has its own variables (you guessed it: these are called environment variables) that define various parameters required for the application to run (e.g., database connection settings). The most common environments are development (or simply dev) test (or testing), stage (or staging), production (prod).
(By the way, minimalistic Kubernetes distributions, such as Minikube and k3s, are often used as the platform for development environments, or sandboxes. We’ve recently published an overview of such solutions.)
Review environments, also known as dynamic or preview environments, are typically used to test the new functionality or showcase it. This comes in handy for development and testing teams, giving them the possibility to quickly deploy new code to the Kubernetes cluster. Thus, they are provided a dedicated environment they can use to verify that the code is correct or for other purposes. At the same time, the testing team gains an opportunity to test new functionality quickly and efficiently.
Let’s take a simple, fairly typical example: imagine a small development team that uses stage and production environments.
While developing new functionality (or improving on some old functions), the developer creates a separate branch and makes the necessary changes to the code. Now, he/she needs to deploy it into the existing cluster quickly. In doing so, the developer must not interfere with the testing team and other fellow developers, since they are already debugging and testing other changes in the deployed environments. This is where review environments can come in handy.
Depending on how a particular team/company’s workflow is arranged, each developer may have one or more “custom” review environments or environments created based on specific branches. Without going into detail (we’ll talk about them later), the typical workflow might go like this:
- The developer makes changes to the code in the local branch and then pushes it to the repository.
- Then, either automatically or manually, the application code gets deployed to the Kubernetes cluster.
- At the same time, there is a pre-made (by the DevOps team) Helm chart in the Git repository. It deploys to the cluster all the software required for the application: MySQL, Redis, Ingress, and Secrets to access external services (such as S3 storage, etc.), as well as the application itself/app components.
- Next, database migrations are performed: various jobs are run to ensure that the “review” database is up-to-date, thus rendering the review environment as close to the production one as possible.
It turns out that a review environment provides a more efficient and flexible way to run code without having to do any extra work:
- no need to install a bunch of dependencies on your local machine or run Docker containers with all the software the application depends on;
- no need to invent scripts to start it all up;
- no need to make sure that all environment variables are defined;
- …
A DevOps engineer who is responsible for building and deploying the application implements all of the above using a Helm chart (or similar tooling). This method is usually quite convenient and universal.
In other words, review environments allow you to test your code in an environment similar to a production one without cluttering up your machine.
To sum it all up, a review environment is usually a “small” single-user environment with limited resources. You can quickly deploy it to a cluster, use it, and delete it. Reproducibility is crucial for such environments since you need to ensure that the code and the image that has undergone debugging, testing, optimization, etc. is deployed to production precisely as it is and that the result of running the application is predictable.
Personally, we use the werf tool to ensure reproducibility. Suppose the application and its dependencies get deployed to the cluster with all the settings, environment variables, etc., while the Docker images are built and tagged using content-based tags. In this case, you can achieve the desired reproducibility level thanks to werf.
NB. This was relevant for werf v1.1. In werf v1.2, the reproducibility guarantees have been extended even further thanks to a feature called Giterminism. The challenges of reproducibility in CI/CD, in general, have been discussed in more detail in this article.
Limited review environments
Limited (or “partial”) review/preview environments are quite popular. They have fewer resources (CPU, memory, disk) than the full ones and reduced functionality (i.e., a reduced set of infrastructure components).
Here is a real-life example. Suppose the developer tweaks the part of the application that only interacts with MySQL. He doesn’t care about all other parts (say, involving Redis and some other infrastructure components). In this case, all you need to do is deploy a MySQL database and the application itself to the cluster. To be more precise, in some cases, you may also need to deploy an Ingress for connecting over HTTP/HTTPS.
Thus, limited environments allow the developer to quickly deploy an application to the cluster, ensure that the code operates as intended, and save cluster resources. That way, you can significantly reduce server costs without sacrificing development speed and convenience. It is worth noting that this approach is only an option if you are confident that the software missing in the environment will not affect the application’s operation.
Since review environments are usually single-user (only a few developers have access to a deployed application), they do not require significant resources. In real life, the required amount could be tens of times(!) lower than that of production and even stage environments.
Usage: How to make a review environment in GitLab
Below, we will demo specific workflow examples and create a GitLab pipeline. Please note that:
- GitLab is our CI/CD system of choice. Of course, you can use other CI/CD systems if you prefer.
- We will use the above-mentioned werf tool in the examples. You do not have to use it; however, werf significantly simplifies implementation.
Creating a repository and review environment pipeline
You can configure a GitLab pipeline using the .gitlab-ci.yml file (note the dot at the beginning and the .yml file extension instead of .yaml).
Create a repository in GitLab and configure the pipeline using the .gitlab-ci.yml file at the repository root. Here are the file contents:
# Specify the global pipeline variables.
# In our case, all we need to specify is the werf version. We will use
# this tool to build the necessary images, deploy the entire environment,
# and remove it from the cluster
variables:
WERF_VERSION: "1.2 beta"
# Define the stages that the pipeline is divided into:
stages:
# building images
- build
# deploying/running and stopping the review environment
- review
before_script:
# Check if trdl is present and, if successful, pull the correct werf version
- type trdl && source $(trdl use werf ${WERF_VERSION})
# Generate and add environment variables for werf to be able to use GitLab
- type werf && source <(werf ci-env gitlab)
Build:
stage: build
# A list of commands to run on the gitlab-runner during the stage start
script:
# Building the images defined in werf.yaml
- werf build
# Exclude the stage from the schedulers
except:
- schedules
# Specify the tag for the gitlab-runner(s) to run the stage on
tags:
- werf
# Define the template for deploying the review environment
Deploy Review:
stage: review
script:
# Invoke werf converge to deploy the chart to the cluster. The --skip-build
# parameter skips the build since we have a separate image-building stage
- werf converge
--skip-build
# This step depends on the Build step; thus, the deploy step will not be
# available if something went wrong during the build step
needs:
- Build
tags:
- werf
# Set the additional environment variables
environment:
name: review/${CI_COMMIT_BRANCH}/${CI_COMMIT_REF_SLUG}
# Specify the step to run for stopping/deleting the review environment
on_stop: Stop Review
# Specify the period after which GitLab will automatically delete
# the review environment
auto_stop_in: 1 day
# The step can only be called for a branch
only:
- branches
# ... and it must be run manually
when: manual
# Exclude the scheduler
except:
- schedules
# Define stopping/deleting the review environment:
Stop Review:
# The stage to which the step belongs
stage: review
# Invoke "werf dismiss" and provide the environment, namespace, and
# Helm release name to delete. The --with-namespace flag deletes
# the namespace in addition to the Helm release resources
script:
- werf dismiss --with-namespace
when: manual
environment:
name: review/${CI_COMMIT_BRANCH}/${CI_COMMIT_REF_SLUG}
action: stop
only:
- branches
tags:
- werf
except:
- schedulesNice! We have created a pipeline that:
- runs the image build process,
- deploys the Helm release to the cluster (if the build was successful),
- stops/deletes it.
And here is how the pipeline defined above will look in GitLab:
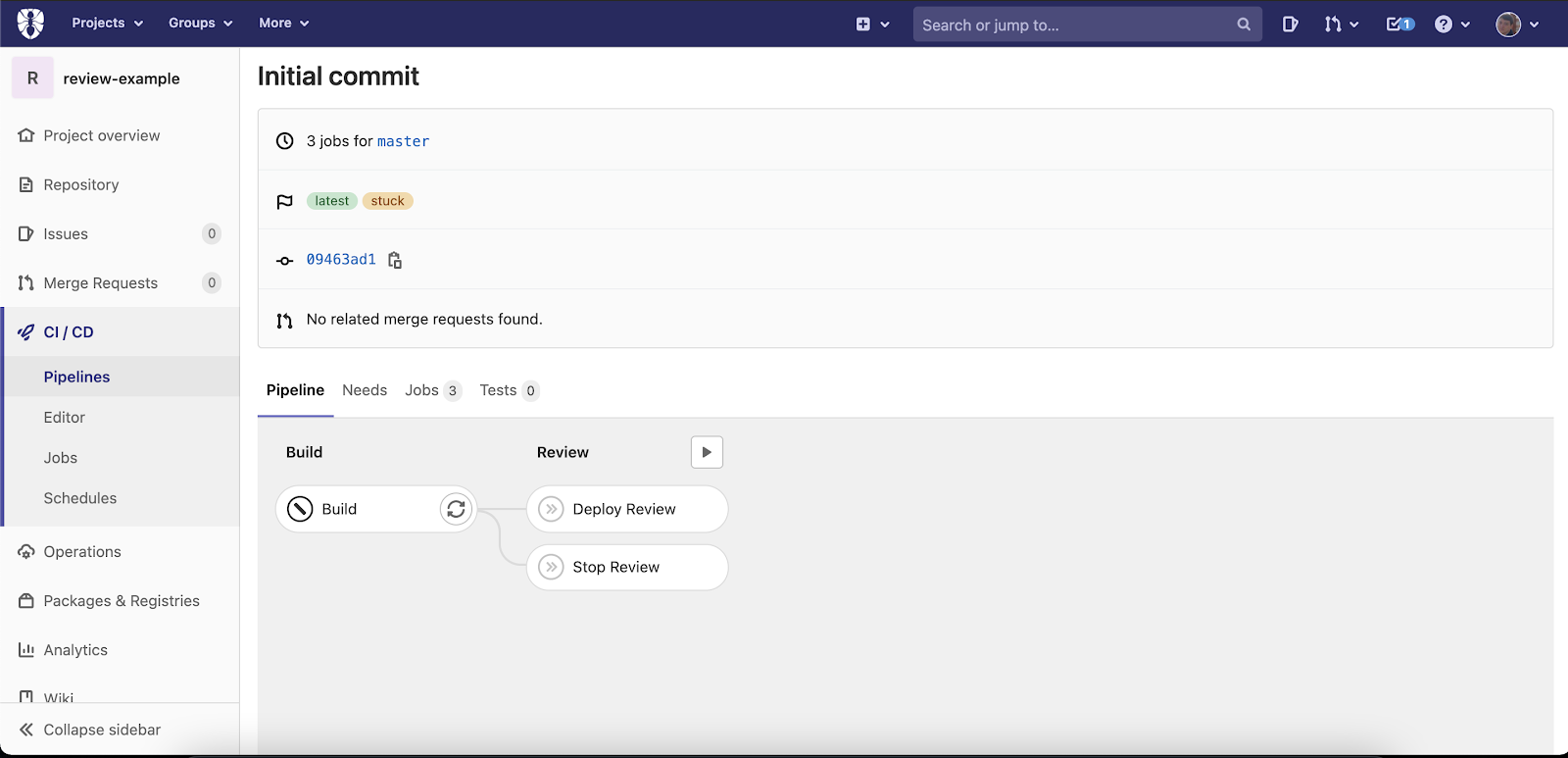
Potential problems and how to fix them
While using review environments, we have encountered several issues as well. Here are the most common among them:
1. Excessive resource consumption
Developers can work on many branches, make multiple merge requests, and deploy a large number of review environments in a single day. All of that may lead to the problem of excessive resource usage.
The GitLab pipeline implemented above only deletes environments that have been running for more than one day; you can also stop/delete them manually.
NB. Please, also note that the auto_stop_in parameter used to stop environments within 1 day has a known limitation described in the documentation: “Due to resource limitations, a background worker for stopping environments only runs once every hour. This means that environments aren’t stopped at the exact timestamp specified, but are instead stopped when the hourly cron worker detects expired environments.”
However, that may not be enough. Limiting the number of review environments in the cluster allows you to tell how many review environments can be run and the total amount of resources consumed.
We will use the .gitlab-ci.yml file to set the maximum number of review environments:
variables:
WERF_VERSION: "1.2 beta"
Deploy to Review:
before_script:
- type trdl && source <(trdl use werf ${WERF_VERSION})
# The maximum number of review environments
- export MAX_REVIEW=${MAX_REVIEW:-3}
# Use the project name from werf.yaml
- "export PROJNAME=$(cat werf.yaml | grep project: | awk '{print $2}')"
# How many review environments are deployed?
- export DEPLOYED_REVIEW=$(helm ls -A -a | grep -F "$PROJNAME-review" | sort | uniq | grep -cv "$PROJNAME-$CI_ENVIRONMENT_SLUG") || export DEPLOYED_REVIEW="0"
- if (( "$DEPLOYED_REVIEW" >= "$MAX_REVIEW" )) && [[ "$CI_ENVIRONMENT_SLUG" =~ "review" ]]; then ( echo "The maximum number ($MAX_REVIEW) of review environments has been reached; stop the unused ones" && exit 1; ); fi
script:
- werf converge
--skip-build
- echo "DYNAMIC_ENVIRONMENT_URL=http://${PROJNAME}-${CI_ENVIRONMENT_SLUG}.kube.some.domain" >> deploy.env
artifacts:
reports:
dotenv: deploy.env
needs:
- Build
tags:
- werf
stage: review
allow_failure: false
environment:
name: review/${CI_COMMIT_BRANCH}/${CI_COMMIT_REF_SLUG}
url: $DYNAMIC_ENVIRONMENT_URL
on_stop: Stop Review
auto_stop_in: 1 day
only:
- branches
except:
- develop
- master
- schedules
when: manual
Stop Review:
stage: review
script:
- werf dismiss --with-namespace
environment:
name: review/${CI_COMMIT_BRANCH}/${CI_COMMIT_REF_SLUG}
when: manual
except:
- develop
- master
- schedules
tags:
- werf
stages:
- build
- reviewSuch an approach allows you to plan server capacities, renders infrastructure costs predictable, and frees your cluster of unnecessary releases.
We also recommend using separate nodes for various non-production deployment environments. This approach will minimize the impact on production in the event of failures/excessive resource consumption and ensure (at the hardware level) that the test/review/stage environments will not eat up all the resources while at the same time rendering infrastructure costs even more predictable.
2. Let’s Encrypt Limits
The second problem (not the most obvious one) relates to LE certificates for review environment domains. Depending on the workflow, there may be a huge number of review environments. The thing is that SSL certificates are provisioned each time review environments are deployed. At some point, you’ll just hit one limit or another.
The most straightforward solution is to use a wildcard certificate for all subdomains. It is provisioned independently of review environments and is copied automatically* into the namespace of the created review environment.
* For example, you can use shell-operator to implement it.
The same is true for domain or wildcard certificates issued by a commercial certification authority. You add the provisioned certificates to the cluster only once and then use them for every review environment (don’t forget to renew certificates before the expiration date).
3. Docker Hub pull limits
This issue is related to the Docker Hub policy. If you deploy a lot during the daytime, you may run into a limit on the number of images you can pull from the Docker Hub and, thus, cause the deployment process to fail. The reason is well known:
The rate limits of 100 container image requests per six hours for anonymous usage, and 200 container image requests per six hours for free Docker accounts are now in effect. Image requests exceeding these limits will be denied until the six- hour window elapses.
All you need to do to avoid this problem is:
- Make sure that the container description does not contain
imagePullPolicy: Always(though you should monitor this parameter for a number of other reasons as well). - Save the required images to your registry and use them for containers.
4. Multipipelines
Multipipeline is about building a pipeline using dependencies or links to other repositories.
When do you use them? Here’s a pretty basic example: suppose you deploy a review environment containing an application. However, this application requires infrastructure services like Redis and MySQL (their deployments are defined in separate repositories) that can be deployed to various namespaces and environments.
What if you don’t use multipipelines? In that case, you have to manually switch to each infrastructure component repository and deploy it to the correct namespace and deployment environment. Furthermore, sometimes it is hard to tell which components an application depends on, which makes deploying the application very tricky.
Multipipelines allow you to trigger jobs from other repositories. Thus, you can create a pipeline that deploys all the required components in addition to the application itself. You do not have to switch between repositories and memorize application dependencies: the components are deployed fully automatically or with a click of a button.
Multipipelines have become free in GitLab starting with version 12.8; the corresponding documentation is available here. This helpful video explains the basic features and discusses some typical use scenarios.
Conclusion
Review or preview environments are an integral part of the modern, dynamic development process. That’s why most of our customers have been using review environments since the very beginning. The few projects that do not use review environments either don’t need them or haven’t yet discovered their full potential.
I hope this article sheds enough light on the review environments’ advantages, problems, and unique features to make you want to try them.
P.S. I’d like to anticipate this one more time: the fact that our examples are based on GitLab does not mean that review environments cannot be implemented using other CI systems.

Comments