

In the age of ubiquitous CI/CD, we regularly encounter a large number of accompanying tools (have you seen that awesome periodic table?..). However, it is GitLab that has become our closest friend, not just for source control but for continuous integration as well. It has also gained a lot of traction in the industry as a whole*.
GitLab developers have tried to keep up with the growing interest in the product, pleasing the community of developers and DevOps engineers with new versions:
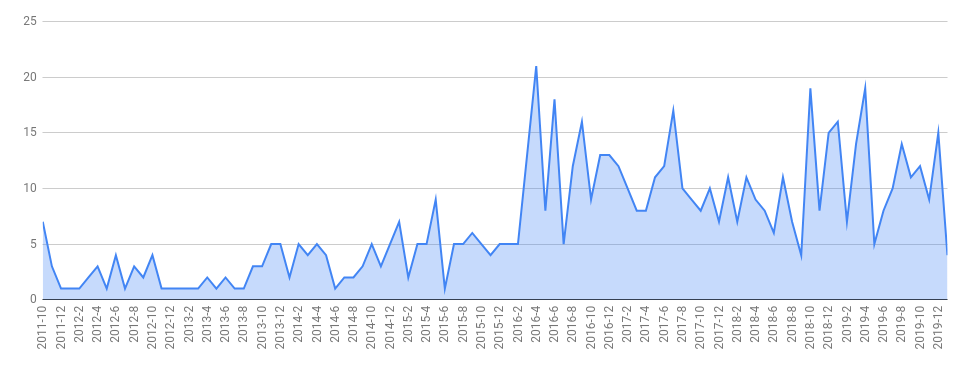
… so this project has become the very case when active development brings a whole lot of new and fascinating opportunities. For potential users, this is just another convincing argument when choosing the tool. However, for existing users, it is pleasantly challenging: if you have not updated your GitLab installation in the last month, then most likely you have missed something interesting (not to mention regular security updates).
In this article, we will discuss the most significant (i.e., most in-demand by our DevOps engineers and customers) features of the latest releases of GitLab Community Edition.
* Just five years ago, many could have asked: “GitLab? You mean GitHub, right?”. Today, the situation is different. For example, Google Trends shows a 5-fold increase in the popularity of the “GitLab” query over the period. That said, there were also some unpleasant moments (or should I say scandals) that happened relatively recently. However, this article is about technology and not politics, so we will not dwell on these questionable “merits” in depth.
#1: needs
- Specify dependencies for the job explicitly
- Introduced in GitLab version: 12.2
- docs.gitlab.com/ce/ci/yaml/#needs
“Wow, dependencies… That’s what I need!” Probably, we were not the only ones who were wrong about the purpose of this parameter… It is used to define a list of previous jobs to fetch artifacts from. Yes, you read it right: artifacts and not the dependency on running the previous task.
Let’s suppose there are jobs in some stage that do not have to be executed, and you can’t assign them to a separate stage due to some reason (or just don’t feel like doing it).
The puzzle:
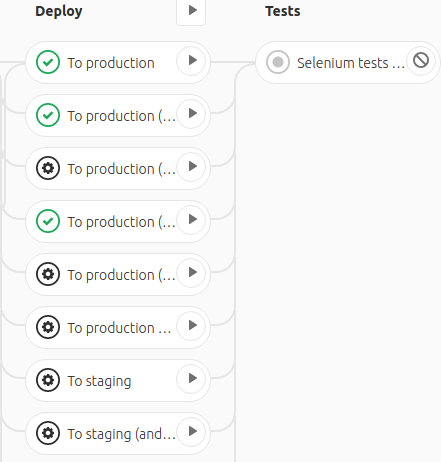
As you can see, the Deploy stage has separate buttons for deploying to both production and staging. However, the Selenium tests job still does not run for some reason. The answer is simple: it waits until all jobs assigned to the previous stage are completed successfully. However, as part of the pipeline, we do not need to deploy the stage to run tests (it was deployed earlier, not with the tag). So what do we do? And here the needs directive comes to the rescue!
With it, we specify only previous jobs that are actually required to run tests:
needs:
- To production (Cluster 1)
- To production (Cluster 2)Now, we have a job that is called when the jobs specified above are complete (without waiting for other jobs to complete):
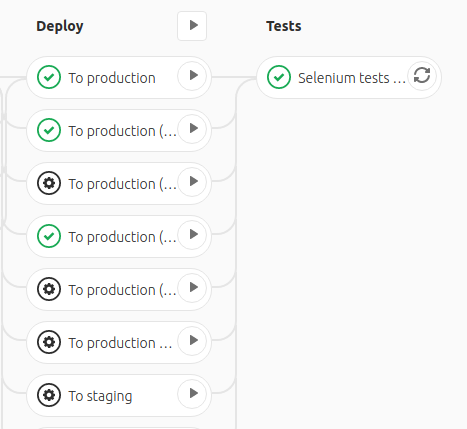
Isn’t it cool? And you know, I used to expect that the dependencies parameter would work like this…
#2: extends
- Extend capabilities of YAML anchors and aliases
- Introduced in GitLab version: 11.3
- docs.gitlab.com/ce/ci/yaml/#extends
Are you tired of reading endless .gitlab-ci.yaml files? Do you miss the code reuse principle? Then you have probably already shaped your .gitlab-ci.yaml to a form similar to the following:
.base_deploy: &base_deploy
stage: deploy
script:
- my_deploy_command.sh
variables:
CLUSTER: "default-cluster"
MY_VAR: "10"
Deploy Test:
<<: *base_deploy
environment:
url: test.example.com
name: test
Deploy Production:
<<: *base_deploy
environment:
url: production.example.com
name: production
variables:
CLUSTER: "prod-cluster"
MY_VAR: "10"Looks good, right? However, if you look closer, you will see something strange. Why didn’t we change variables.CLUSTER only (for our production) but also specify variables.MY_VAR=10 for the second time? Shouldn’t this variable be retrieved from the base_deploy? It turns out it should not: when redefining parameters obtained from the anchor, YAML does not append the contents of matching fields but replaces them. That is why we have to re-specify the variables in the matching sections.
Extends allows us to not just overwrite the field (as is the case with an anchor), but to perform a smart merge:
.base_deploy:
stage: deploy
script:
- my_deploy_command.sh
variables:
CLUSTER: "default-cluster"
MY_VAR: "10"
Deploy Production:
extends: .base_deploy
environment:
url: production.example.com
name: production
variables:
CLUSTER: "prod-cluster"Here, the resulting Deploy Production job would contain both the default MY_VAR variable and the redefined CLUSTER variable.
You might say: “So what is the big deal?”. Imagine: you have a single base_deploy, and, say, a couple of dozen environments that are deployed in the same way. You have to pass different cluster, environment.name parameters, while at the same time preserving the specific set of variables and overlapping fields… This little trick allowed us to substantially (in 2–3 times!) reduce the description of how plenty dev environments should be deployed.
#3: include
- Split the large YAML file into smaller parts and reuse them in other projects
- Introduced in GitLab Core starting with version 11.4
- docs.gitlab.com/ce/ci/yaml/#include
Does your .gitlab-ci.yaml still look like a monstrous manual for a vacuum cleaner in 20 languages (of which you can speak only one), meaning it is very tough to read due to numerous opaque and confusing jobs?
The well-known programming directive include comes to the rescue:
stages:
- test
- build
- deploy
variables:
VAR_FOR_ALL: 42
include:
- local: .gitlab/ci/test.yml
- local: .gitlab/ci/build.yml
- local: .gitlab/ci/deploy-base.yml
- local: .gitlab/ci/deploy-production.ymlIn other words, now you can focus on deploying to production, while the testers can modify their files (and you may even not look at those files). Besides, it allows you to avoid merge conflicts: to be honest, sometimes it can be rather challenging to understand someone else’s code.
But what if you know pipelines for each of your dozen projects inside and out and can explain the logic of every job in them? How will this help us? Those enlightened in code reuse and those who have many similar projects can do the following:
- include GitLab CI files from another repository of the same GitLab instance via include:file,
- include collections of ready-made GitLab templates via include:template,
- include a file from a different location using HTTP/HTTPS via include:remote.
Now you know how to deploy a bunch of similar projects (they may differ in code but still are deployed in the same fashion) easily and quickly, and how to do it without the need to keep the CI up-to-date in all repositories!
We have also revealed a real-life example of using include in this article.
#4: only/except refs
- Define complex conditions, including variables and file changes
- Since this is an extended family of functions, some parts of it have been introduced in GitLab 10.0, others (such as
changes) have become available in version 11.4 - docs.gitlab.com/ce/ci/yaml/#onlyexcept-advanced
Sometimes I think that it is not we who control the pipeline, but the pipeline that controls us. However the only/except directives are excellent tools (now more advanced) to make a difference. What does this mean?
In the simplest (and, perhaps, the most enjoyable) case it means the ability to skip stages:
Tests:
only:
- master
except:
refs:
- schedules
- triggers
variables:
- $CI_COMMIT_MESSAGE =~ /skip tests/In the above example, the job runs for the master branch only, and it cannot be initiated by a scheduler or a trigger (GitLab differentiates between API and trigger calls, although they are essentially the same API). Besides, the job will not be run if a commit message contains the “skip tests” keyphrase. For example, you have fixed a typo in the README.md or the documentation — “skip tests” would allow you to avoid unnecessary testing in this case.
“Hey, it’s 2020! Why do I have to explain to my “number-cruncher” that there is no need to run tests every time the documentation changes?” And indeed: only:changes allows you to run tests when files are changed only in specific directories. For example:
only:
refs:
- master
- merge_requests
changes:
- "front/**/*"
- "jest.config.js"
- "package.json"And for the reverse action (i.e., do not run tests) there is exception:changes.
#5: rules
- Define individual rule objects for the job
- Introduced in GitLab version: 12.3
- docs.gitlab.com/ce/ci/yaml/#rules
This directive is similar to the above only:* but with a major difference: it allows you to specify the when parameter. For example, if you do not want to abandon the possibility of running the job altogether, you can provide a button. The user will use it to run a job (if needed) without starting a new pipeline or making a commit.
#6: environment:auto_stop_in
- Stop inactive environments
- Introduced in GitLab version: 12.8
- docs.gitlab.com/ce/ci/yaml/#environmentauto_stop_in
We learned about this feature right before this article was finished and have not had time to try it in real life… but it is definitely the feature we have always wanted to have in several of our projects!
In GitLab, environments might have the on_stop keyword. It is a useful feature if you need to create and delete environments dynamically (for example, for each branch). The job defined under on_stop runs, for example, when merging the MR into the master branch or closing it (or even at a push of a button). Thus, the unnecessary environment is automatically deleted.
Well, everything seems logical and works fine, except for the human factor. Many developers merge MRs not by pressing a button in GitLab, but locally via git merge. Who can blame them: that is so convenient! The problem is that on_stop does not work in this case, and lost environments pile up over time. This is where the long-awaited auto_stop_in comes in handy.
Bonus: temporary solutions when options are limited
Despite all these (and many other) useful features of GitLab, sometimes you simply cannot define the conditions for running a job using currently available capabilities.
GitLab is not perfect, but it provides basic tools for building pipelines of your dreams… That is, of course, if you are determined to go beyond the basic DSL and dive into the world of scripting. Below we provide several solutions based on our experience. They should not be regarded as ideologically correct or recommended. However, they illustrate various options when built-in API functionality is not enough.
Workaround #1: starting two jobs with one click
script:
- >
export CI_PROD_CL1_JOB_ID=`curl -s -H "PRIVATE-TOKEN: ${GITLAB_API_TOKEN}" \
"https://gitlab.domain/api/v4/projects/${CI_PROJECT_ID}/pipelines/${CI_PIPELINE_ID}/jobs" | \
jq '[.[] | select(.name == "Deploy (Cluster 1)")][0] | .id'`
- >
export CI_PROD_CL2_JOB_ID=`curl -s -H "PRIVATE-TOKEN: ${GITLAB_API_TOKEN}" \
"https://gitlab.domain/api/v4/projects/${CI_PROJECT_ID}/pipelines/${CI_PIPELINE_ID}/jobs" | \
jq '[.[] | select(.name == "Deploy (Cluster 2)")][0] | .id'`
- >
curl -s --request POST -H "PRIVATE-TOKEN: ${GITLAB_API_TOKEN}" \
"https://gitlab.domain/api/v4/projects/${CI_PROJECT_ID}/jobs/$CI_PROD_CL1_JOB_ID/play"
- >
curl -s --request POST -H "PRIVATE-TOKEN: ${GITLAB_API_TOKEN}" \
"https://gitlab.domain/api/v4/projects/${CI_PROJECT_ID}/jobs/$CI_PROD_CL2_JOB_ID/play"And why not if we can?
Workaround #2: transferring rb files for rubocop that were changed in the MR inside the image
Rubocop: stage: test allow_failure: false script: ... - export VARFILE=$(mktemp) - export MASTERCOMMIT=$(git merge-base origin/master HEAD) - echo -ne 'CHANGED_FILES=' > ${VARFILE} - if [ $(git --no-pager diff --name-only ${MASTERCOMMIT} | grep '.rb There is no.gitin the image, so we had to find a workaround in order to check only files that have been modified. Note: That is not a standard situation. Rather, it is a desperate attempt to meet multiple conditions of a task, the description of which extends beyond the scope of this article.Workaround #3: triggering jobs from other repositories during deployment
before_script: - | echo '### Trigger review: infra' curl -s -X POST \ -F "token=$REVIEW_TOKEN_INFRA" \ -F "ref=master" \ -F "variables[REVIEW_NS]=$CI_ENVIRONMENT_SLUG" \ -F "variables[ACTION]=auto_review_start" \ https://gitlab.example.com/api/v4/projects/${INFRA_PROJECT_ID}/trigger/pipelineDeploying microservice into a newly created environment as a dependency is an apparent and essential mechanism. But it does not exist yet, that is why you have to use API calls and the feature described above:
only: refs: - triggers variables: - $ACTION == "auto_review_start"Notes:
- The job under trigger is created before it is possible to bind it to a passing variable to the API (similar to the workaround #1). It would be more logical to implement it via the API by passing the name of the job.
- The function is available in the commercial edition (EE) of GitLab, but it is beyond the scope of this article.
Conclusion
GitLab tries to keep up with the trends, gradually implementing sought-after and useful features*. They are simple to use, and when the basic features are insufficient, you can always extend them with scripts. But then again, the question of maintenance arises. All we can do is to wait for new GitLab releases (or contribute to the project).
The most recent proof is “18 GitLab features are moving to open source”. Here, we’d like to especially anticipate the “Build and share packages in Package” feature. It allows you to put all your packages (from Conan, Maven, NPM, NuGet) in one place.
| wc -w |awk '{print $1}') -gt 0 ]; then
git --no-pager diff --name-only ${MASTERCOMMIT} | grep '.rbThere is no.gitin the image, so we had to find a workaround in order to check only files that have been modified.Note: That is not a standard situation. Rather, it is a desperate attempt to meet multiple conditions of a task, the description of which extends beyond the scope of this article.
Workaround #3: triggering jobs from other repositories during deployment
Deploying microservice into a newly created environment as a dependency is an apparent and essential mechanism. But it does not exist yet, that is why you have to use API calls and the feature described above:
Notes:
- The job under trigger is created before it is possible to bind it to a passing variable to the API (similar to the workaround #1). It would be more logical to implement it via the API by passing the name of the job.
- The function is available in the commercial edition (EE) of GitLab, but it is beyond the scope of this article.
Conclusion
GitLab tries to keep up with the trends, gradually implementing sought-after and useful features*. They are simple to use, and when the basic features are insufficient, you can always extend them with scripts. But then again, the question of maintenance arises. All we can do is to wait for new GitLab releases (or contribute to the project).
The most recent proof is “18 GitLab features are moving to open source”. Here, we’d like to especially anticipate the “Build and share packages in Package” feature. It allows you to put all your packages (from Conan, Maven, NPM, NuGet) in one place.
|tr '\n' ' ' >> ${VARFILE} ;
fi
- if [ $(wc -w ${VARFILE} | awk '{print $1}') -gt 1 ]; then
werf --stages-storage :local run rails-dev --docker-options="--rm --user app --env-file=${VARFILE}" -- bash -c /scripts/rubocop.sh ;
fi
- rm ${VARFILE}
There is no.gitin the image, so we had to find a workaround in order to check only files that have been modified.Note: That is not a standard situation. Rather, it is a desperate attempt to meet multiple conditions of a task, the description of which extends beyond the scope of this article.
Workaround #3: triggering jobs from other repositories during deployment
Deploying microservice into a newly created environment as a dependency is an apparent and essential mechanism. But it does not exist yet, that is why you have to use API calls and the feature described above:
Notes:
- The job under trigger is created before it is possible to bind it to a passing variable to the API (similar to the workaround #1). It would be more logical to implement it via the API by passing the name of the job.
- The function is available in the commercial edition (EE) of GitLab, but it is beyond the scope of this article.
Conclusion
GitLab tries to keep up with the trends, gradually implementing sought-after and useful features*. They are simple to use, and when the basic features are insufficient, you can always extend them with scripts. But then again, the question of maintenance arises. All we can do is to wait for new GitLab releases (or contribute to the project).
The most recent proof is “18 GitLab features are moving to open source”. Here, we’d like to especially anticipate the “Build and share packages in Package” feature. It allows you to put all your packages (from Conan, Maven, NPM, NuGet) in one place.

Comments